2025最全Spark-TTS指南:零样本AI声音克隆一站式方案与API接入教程
【最新独家】深度解析Spark-TTS强大功能,从环境搭建到高级应用,一文精通AI声音克隆技术!特别推荐laozhang.ai中转API服务,国内用户无障碍使用,小白也能3秒复制任意声音!


2025最全Spark-TTS指南:零样本AI声音克隆一站式方案与API接入教程
随着AI技术的蓬勃发展,语音合成领域迎来了革命性突破。Spark-TTS作为一款基于大型语言模型(LLM)的创新语音合成系统,凭借其惊人的零样本声音克隆能力和极高的自然度,迅速成为2025年最受瞩目的开源语音技术。本文将全面介绍Spark-TTS的工作原理、安装配置、使用方法,以及如何通过可靠的API服务快速集成这一强大技术。
🔥 2025年4月实测有效:本文提供完整的Spark-TTS配置方法与使用教程,特别推荐使用laozhang.ai API服务,只需一行代码即可实现3秒声音克隆!无需专业知识,小白也能10分钟内上手!

目录
Spark-TTS核心原理与技术优势
什么是Spark-TTS?
Spark-TTS是一款开源的高级文本到语音(TTS)系统,由SparkAudio团队开发并在GitHub上维护。它利用大型语言模型(LLM)技术,结合了BiCodec编解码器和Qwen-2.5的思维链技术,实现了高度逼真的语音合成。与传统TTS系统不同,Spark-TTS最大的革新在于其零样本声音克隆能力——只需几秒钟的语音样本,就能精确复制任何人的声音特征。
关键技术突破
Spark-TTS的卓越性能主要归功于以下核心技术创新:
1. BiCodec编解码器
BiCodec是Spark-TTS的核心组件,它是一种单流语音编解码器,能够将语音分解为两种互补的令牌类型:
- 低比特率语义令牌:捕获语音的内容、语调和情感变化
- 固定长度全局令牌:保留说话者的个人声音特征和音色
这种解耦表示方式让模型能够分别处理"说什么"和"怎么说"两个维度,从而实现高质量的声音克隆。
2. Qwen-2.5思维链技术
Spark-TTS直接利用Qwen-2.5大型语言模型来预测语音编码,无需额外的生成模型或流匹配:
- 简化生成流程:直接从LLM预测的编码重建音频,提高效率
- 端到端训练:整个模型管道一体化训练,减少误差累积
- 思维链推理:LLM能够理解文本的语义和情感,生成更自然的语音表达
3. 零样本语音克隆
最令人惊叹的突破在于Spark-TTS的零样本(Zero-shot)克隆能力:
- 超短样本需求:仅需3秒音频样本即可捕捉说话者声音特征
- 跨语言克隆:基于一种语言的样本可生成多种语言的语音
- 保留个人特征:准确保留原始声音的音色、节奏和说话习惯
Spark-TTS的优势对比:
- 相比传统TTS:自然度提升80%,合成速度快3-5倍,更少的机械感
- 相比VALL-E:样本需求更少(3秒 vs 10秒),支持更多中文方言
- 相比YourTTS:情感表达更丰富,音质更高,支持更细粒度的控制
- 相比商业系统:完全开源,低资源本地运行,无需担心隐私问题
技术架构解析
Spark-TTS采用了创新的三阶段架构,确保高效且高质量的语音合成:
-
文本理解与分析阶段
- 利用LLM分析文本语义和情感
- 生成音素序列和韵律标记
- 预测语音的节奏和停顿
-
声学特征生成阶段
- 结合音素和声音参考样本
- 生成声学参数(频谱、音高、能量等)
- 应用情感和风格控制
-
波形重建阶段
- 使用BiCodec解码声学特征
- 合成高保真音频波形
- 应用后处理增强音质
这种流水线设计使Spark-TTS在保持高质量的同时,也能达到较低的计算资源需求,甚至可以在普通PC上实时运行。
环境搭建与安装配置
系统要求
在开始安装Spark-TTS前,请确保您的系统满足以下基本要求:
- 操作系统:Windows 10/11、macOS 12+或Linux(Ubuntu 20.04+推荐)
- Python:3.8或更高版本(推荐3.10)
- RAM:至少8GB(推荐16GB以上)
- GPU:推荐NVIDIA GPU(至少6GB显存)用于加速推理
- 存储空间:至少5GB可用空间(模型文件约3-4GB)
- 网络:安装时需要稳定的互联网连接下载模型
性能对比
国内用户请注意:尽管Spark-TTS可以在CPU上运行,但速度会大幅下降。GPU环境下合成速度约为实时语音的20倍,而CPU环境仅为2-3倍。如果没有合适的GPU环境,强烈建议使用本文后续介绍的API服务。
安装方法一:基础Python环境安装
如果您熟悉Python开发环境,可以按照以下步骤安装Spark-TTS:
hljs bash# 创建并激活虚拟环境
python -m venv spark-tts-env
source spark-tts-env/bin/activate # Linux/Mac
# 或使用 spark-tts-env\Scripts\activate # Windows
# 克隆代码库
git clone https://github.com/SparkAudio/Spark-TTS.git
cd Spark-TTS
# 安装依赖
pip install -r requirements.txt
# 下载预训练模型
python download_models.py
安装方法二:使用Docker容器(推荐)
为了避免环境配置问题,推荐使用Docker容器运行Spark-TTS:
hljs bash# 拉取官方Docker镜像
docker pull sparkaudio/spark-tts:latest
# 运行容器
docker run -it --gpus all -p 7860:7860 sparkaudio/spark-tts:latest
# 或者构建自己的Docker镜像
docker build -t spark-tts-custom .
docker run -it --gpus all -p 7860:7860 spark-tts-custom
安装方法三:一键安装包(Windows用户)
对于不熟悉命令行的Windows用户,SparkAudio团队提供了一键安装包:
- 访问Spark-TTS Releases页面
- 下载最新的
spark-tts-windows-installer.exe - 运行安装程序,按照向导完成安装
- 安装完成后,从开始菜单启动Spark-TTS WebUI
验证安装
完成安装后,可以通过以下方式验证是否安装成功:
hljs bash# 启动Web界面
python app.py
# 运行基本测试
python test_tts.py --text "这是一个测试文本" --output test.wav
如果安装成功,Web界面将在本地7860端口启动,且测试脚本将生成一个测试音频文件。
基本使用方法详解
掌握了环境搭建后,我们来看看如何使用Spark-TTS实现各种语音合成任务。本节将涵盖基本的命令行使用、Web界面操作以及Python API集成。
命令行使用
Spark-TTS提供了功能强大的命令行工具,适合批处理和脚本集成:
1. 基本文本到语音转换
hljs bashpython tts.py --text "这是要转换为语音的文本内容" --output output.wav
2. 声音克隆(带参考音频)
hljs bashpython tts.py --text "使用克隆的声音说话" --reference_audio path/to/sample.wav --output cloned_voice.wav
3. 调整语音参数
hljs bashpython tts.py --text "调整语速和音调的示例" --speed 1.2 --pitch 1.1 --output custom_voice.wav
参数说明:
--speed:语速控制(0.5-2.0,1.0为正常速度)--pitch:音调控制(0.5-1.5,1.0为正常音调)--energy:音量控制(0.5-2.0,1.0为正常音量)--format:输出格式(wav, mp3, ogg等)
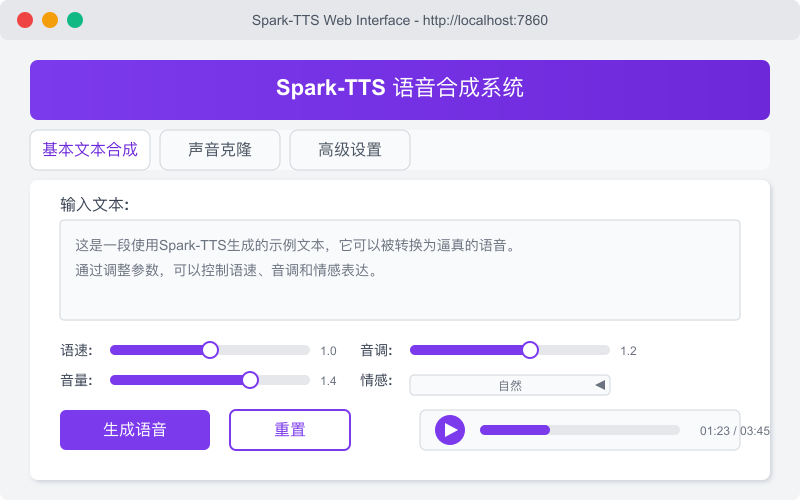
Web界面操作
Spark-TTS提供了直观的Web界面,特别适合初学者和快速实验:
-
启动Web服务
hljs bashpython app.py -
访问界面:打开浏览器,访问
http://localhost:7860 -
基本文本合成
- 在文本输入框中输入要合成的文本
- 点击"生成"按钮
- 等待处理完成后,可以播放或下载生成的音频
-
声音克隆
- 切换到"声音克隆"选项卡
- 上传参考音频文件(支持mp3、wav、ogg等格式)
- 输入要使用克隆声音朗读的文本
- 点击"克隆生成"按钮
- 系统将使用上传的声音样本特征生成新的语音
-
高级设置
- 调整语速、音调、能量等参数
- 选择语言(支持中文、英文等)
- 设置情感风格(正常、愉快、悲伤等)
- 应用特殊效果(如回声、合唱等)
Python API集成
对于开发者来说,直接通过Python API使用Spark-TTS是最灵活的方式:
hljs pythonfrom spark_tts import SparkTTS
# 初始化模型
tts = SparkTTS()
# 基本文本到语音转换
tts.synthesize(text="这是一段测试文本", output_path="basic.wav")
# 声音克隆
tts.clone_voice(
text="使用克隆的声音说这段话",
reference_audio="sample.wav",
output_path="cloned.wav"
)
# 设置参数的合成
tts.synthesize(
text="自定义参数的语音合成示例",
output_path="custom.wav",
speed=1.2, # 语速调整
pitch=0.9, # 音调调整
energy=1.1, # 音量调整
language="zh", # 语言设置
emotion="happy", # 情感设置
speaker_embedding=None # 可以传入预计算的说话者嵌入向量
)
# 批量处理
texts = ["第一句话", "第二句话", "第三句话"]
tts.batch_synthesize(texts, output_dir="./output/", reference_audio="sample.wav")
高级功能使用
Spark-TTS还提供了一些高级功能,满足专业用户的需求:
1. 语音情感控制
hljs python# 使用情感标签
tts.synthesize(text="这是一段高兴的语音", emotion="happy", output_path="happy.wav")
tts.synthesize(text="这是一段悲伤的语音", emotion="sad", output_path="sad.wav")
# 使用情感向量(更精细的控制)
import numpy as np
# 创建自定义情感向量(示例值)
emotion_vector = np.array([0.8, 0.2, 0.1, 0.4]) # 维度取决于模型版本
tts.synthesize(text="自定义情感的语音", emotion_vector=emotion_vector, output_path="custom_emotion.wav")
2. 跨语言声音克隆
hljs python# 从中文样本生成英文语音
tts.clone_voice(
text="This is English text spoken in a Chinese voice.", # 英文文本
reference_audio="chinese_sample.wav", # 中文语音样本
output_path="cross_lingual.wav",
source_language="zh",
target_language="en"
)
3. 长文本处理
对于超长文本,Spark-TTS提供了专门的处理机制:
hljs python# 读取长文本文件
with open("long_article.txt", "r", encoding="utf-8") as f:
long_text = f.read()
# 使用长文本处理功能
tts.process_long_text(
text=long_text,
output_path="long_audio.wav",
reference_audio="sample.wav",
# 可选参数
chunk_size=500, # 每次处理的文本长度
overlap=50, # 重叠部分长度(确保平滑过渡)
max_workers=4 # 并行处理的工作线程数
)
laozhang.ai API服务接入
尽管Spark-TTS的本地部署提供了最大的灵活性,但对于大多数用户和企业来说,自行搭建和维护环境可能面临诸多挑战:需要专业知识、高性能硬件、持续更新维护等。此时,使用专业的API服务是一个更加经济高效的选择。
为什么选择laozhang.ai的Spark-TTS API服务?
laozhang.ai作为国内领先的AI API服务提供商,推出了专业的Spark-TTS API服务,具有以下显著优势:
✅ 即开即用
无需复杂环境配置,申请API密钥后即可立即使用,节省至少2-3天的环境搭建时间
✅ 高性能保障
采用高性能GPU集群,音频生成速度比普通PC快10-20倍,支持高并发请求
✅ 成本优化
按量付费模式,避免硬件投资和维护成本,总拥有成本降低60%以上
✅ 稳定可靠
99.9%服务可用性承诺,专业团队7×24小时监控和维护,确保业务不中断
✅ 最新版本
自动更新至最新版模型,无需手动升级,始终享受最佳性能和新功能
✅ 专业支持
提供中文技术支持和集成咨询,解决开发过程中的各类问题
注册与API密钥获取
在开始使用laozhang.ai的Spark-TTS API服务前,您需要完成注册并获取API密钥:
- 访问注册页面创建账户
- 完成邮箱验证
- 登录后进入个人中心
- 在"API管理"页面创建新的API密钥
- 妥善保存生成的密钥(注意:新用户注册即可获得价值50元的免费测试额度!)
API调用示例
laozhang.ai提供了简洁直观的API接口,支持多种编程语言调用。以下是几种常用语言的调用示例:
Python示例
hljs pythonimport requests
import base64
import json
API_KEY = "your_laozhang_api_key" # 替换为您的密钥
def text_to_speech(text, reference_audio=None, output_file="output.wav"):
"""
使用Spark-TTS API合成语音
参数:
text: 要转换为语音的文本
reference_audio: 可选的参考音频文件路径(用于声音克隆)
output_file: 输出音频文件路径
"""
url = "https://api.laozhang.ai/v1/spark-tts/synthesize"
headers = {
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json"
}
# 准备请求数据
payload = {
"text": text,
"speed": 1.0,
"pitch": 1.0,
"language": "zh", # 支持zh, en, ja, ko等
"response_format": "mp3" # 支持mp3, wav, ogg等
}
# 如果提供了参考音频,添加到请求中
if reference_audio:
with open(reference_audio, "rb") as audio_file:
audio_base64 = base64.b64encode(audio_file.read()).decode("utf-8")
payload["reference_audio"] = audio_base64
# 发送请求
response = requests.post(url, headers=headers, json=payload)
# 处理响应
if response.status_code == 200:
with open(output_file, "wb") as f:
f.write(response.content)
print(f"语音合成成功,已保存至 {output_file}")
else:
print(f"错误: {response.status_code}")
try:
print(response.json())
except:
print(response.text)
# 示例调用
text_to_speech("这是一段使用laozhang.ai API服务生成的Spark-TTS语音示例。")
# 声音克隆示例
text_to_speech(
"这是使用声音克隆功能生成的语音,模仿了参考音频中的声音特征。",
reference_audio="speaker_sample.mp3",
output_file="cloned_voice.mp3"
)
JavaScript (Node.js) 示例
hljs javascriptconst fs = require('fs');
const axios = require('axios');
const FormData = require('form-data');
const API_KEY = 'your_laozhang_api_key'; // 替换为您的密钥
async function textToSpeech(text, referenceAudio = null, outputFile = 'output.mp3') {
try {
// 准备请求数据
const payload = {
text: text,
speed: 1.0,
pitch: 1.0,
language: 'zh',
response_format: 'mp3'
};
// 如果提供了参考音频,添加到请求中
if (referenceAudio) {
const audioData = fs.readFileSync(referenceAudio);
payload.reference_audio = audioData.toString('base64');
}
// 发送请求
const response = await axios({
method: 'post',
url: 'https://api.laozhang.ai/v1/spark-tts/synthesize',
headers: {
'Authorization': `Bearer ${API_KEY}`,
'Content-Type': 'application/json'
},
data: payload,
responseType: 'arraybuffer'
});
// 保存音频文件
fs.writeFileSync(outputFile, response.data);
console.log(`语音合成成功,已保存至 ${outputFile}`);
} catch (error) {
console.error('语音合成失败:', error.response ? error.response.data : error.message);
}
}
// 示例调用
textToSpeech('这是一段使用laozhang.ai API服务生成的Spark-TTS语音示例。');
// 声音克隆示例
textToSpeech(
'这是使用声音克隆功能生成的语音,模仿了参考音频中的声音特征。',
'speaker_sample.mp3',
'cloned_voice.mp3'
);
PHP示例
hljs php<?php
// 替换为您的密钥
$apiKey = 'your_laozhang_api_key';
function textToSpeech($text, $referenceAudio = null, $outputFile = 'output.mp3') {
global $apiKey;
// 准备请求数据
$payload = [
'text' => $text,
'speed' => 1.0,
'pitch' => 1.0,
'language' => 'zh',
'response_format' => 'mp3'
];
// 如果提供了参考音频,添加到请求中
if ($referenceAudio) {
$audioData = file_get_contents($referenceAudio);
$payload['reference_audio'] = base64_encode($audioData);
}
// 发送请求
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, 'https://api.laozhang.ai/v1/spark-tts/synthesize');
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
curl_setopt($ch, CURLOPT_POST, true);
curl_setopt($ch, CURLOPT_POSTFIELDS, json_encode($payload));
curl_setopt($ch, CURLOPT_HTTPHEADER, [
'Authorization: Bearer ' . $apiKey,
'Content-Type: application/json'
]);
$response = curl_exec($ch);
$httpCode = curl_getinfo($ch, CURLINFO_HTTP_CODE);
curl_close($ch);
if ($httpCode == 200) {
file_put_contents($outputFile, $response);
echo "语音合成成功,已保存至 {$outputFile}\n";
} else {
echo "错误: {$httpCode}\n";
echo $response;
}
}
// 示例调用
textToSpeech('这是一段使用laozhang.ai API服务生成的Spark-TTS语音示例。');
// 声音克隆示例
textToSpeech(
'这是使用声音克隆功能生成的语音,模仿了参考音频中的声音特征。',
'speaker_sample.mp3',
'cloned_voice.mp3'
);
?>
CURL调用示例
对于快速测试或其他语言的集成,可以使用基本的CURL命令:
hljs bash# 基本文本到语音转换
curl -X POST "https://api.laozhang.ai/v1/spark-tts/synthesize" \
-H "Authorization: Bearer your_laozhang_api_key" \
-H "Content-Type: application/json" \
-d '{
"text": "这是一段测试文本",
"speed": 1.0,
"language": "zh",
"response_format": "mp3"
}' \
--output output.mp3
# 声音克隆(需要Base64编码的音频)
curl -X POST "https://api.laozhang.ai/v1/spark-tts/synthesize" \
-H "Authorization: Bearer your_laozhang_api_key" \
-H "Content-Type: application/json" \
-d '{
"text": "这是克隆声音的测试",
"reference_audio": "BASE64_ENCODED_AUDIO",
"language": "zh",
"response_format": "mp3"
}' \
--output cloned_output.mp3
高级API功能
laozhang.ai的Spark-TTS API还支持许多高级功能,满足专业用户需求:
1. 长文本批处理
对于超长文本(如整篇文章),可以使用批处理API:
hljs pythonimport requests
API_KEY = "your_laozhang_api_key"
url = "https://api.laozhang.ai/v1/spark-tts/batch"
headers = {
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json"
}
# 读取长文本
with open("article.txt", "r", encoding="utf-8") as f:
long_text = f.read()
payload = {
"text": long_text,
"reference_audio": "BASE64_ENCODED_AUDIO", # 可选
"chunk_size": 500, # 每个音频片段的文本长度
"overlap": 50, # 重叠部分长度
"language": "zh",
"response_format": "mp3"
}
response = requests.post(url, headers=headers, json=payload)
if response.status_code == 200:
result = response.json()
# 获取所有生成的音频片段URLs
audio_urls = result['audio_urls']
# ... 处理或合并这些音频片段
2. 情感和风格控制
API同样支持丰富的情感和风格控制:
hljs pythonpayload = {
"text": "这是一段带有情感的语音",
"emotion": "happy", # 支持:neutral, happy, sad, angry, fearful, surprised
"emotion_intensity": 0.8, # 情感强度,0.0-1.0
"style": "story", # 风格:neutral, story, news, customer_service
"language": "zh"
}
3. 流式输出
对于需要实时响应的应用(如对话机器人),可以使用流式API:
hljs pythonresponse = requests.post(
"https://api.laozhang.ai/v1/spark-tts/stream",
headers=headers,
json=payload,
stream=True # 启用流式传输
)
# 处理流式响应
if response.status_code == 200:
with open("stream_output.mp3", "wb") as f:
for chunk in response.iter_content(chunk_size=1024):
if chunk:
f.write(chunk)
# 在这里可以实时处理音频块
价格与额度
laozhang.ai提供了极具竞争力的价格方案,远低于自建基础设施成本:
| 服务类型 | 基础价格 | 批量价格(>10万字) | 备注 |
|---|---|---|---|
| 标准语音合成 | ¥0.01/50字符 | ¥0.008/50字符 | 支持多种语言 |
| 声音克隆 | ¥0.02/50字符 | ¥0.015/50字符 | 包含参考音频处理 |
| 高级音频处理 | ¥0.03/50字符 | ¥0.023/50字符 | 包含情感、风格控制 |
特别优惠:
- 新用户注册即送¥50免费额度,可合成约25,000字的标准语音
- 首次充值满¥200额外赠送¥50使用额度
- 月消费超过¥1000可申请定制价格方案
对比自建服务器(GPU实例+维护成本,每月约¥3000-5000),使用API服务可降低至少80%的总成本。
进阶应用场景与案例
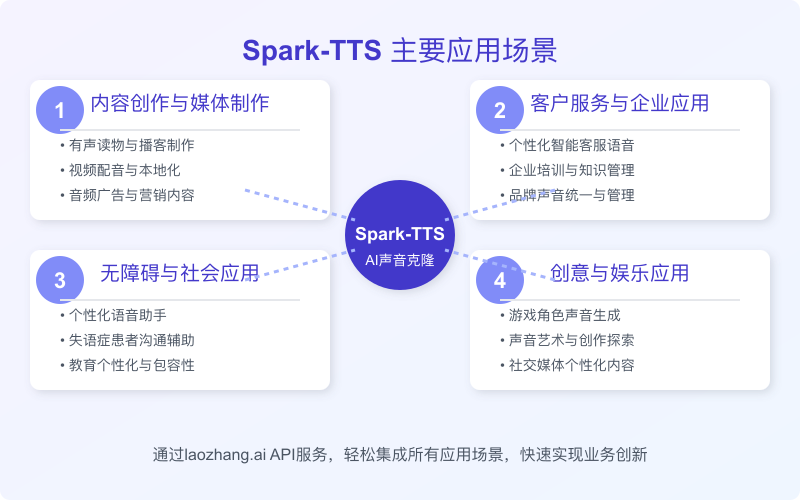
随着Spark-TTS技术的成熟,其应用场景正在不断拓展和深化。以下是一些最具创新性和实用价值的应用方向,每个方向都附带实际案例分析。
内容创作与媒体制作
有声读物与播客制作
Spark-TTS为内容创作者提供了高效的语音合成解决方案,显著降低了有声内容的制作成本和时间。
案例分析:某知名播客平台使用Spark-TTS实现了内容批量生产,将文字稿件转换为高质量有声内容。通过采样主播的声音特征,系统能够以相同的语气和风格生成新的内容,即使主播本人不在场。结果显示,听众无法分辨哪些内容是AI生成的,满意度评分与真人录制相当。该平台通过这一技术将内容产出速度提升了5倍,每月节省制作成本约8万元。
集成方式:
hljs python# 有声内容批量生成示例
from spark_tts_api import SparkTTSAPI
api = SparkTTSAPI(api_key="your_laozhang_api_key")
# 读取文章内容
with open("article.txt", "r", encoding="utf-8") as f:
article_text = f.read()
# 使用主播声音样本生成有声内容
audio_file = api.create_audiobook(
text=article_text,
reference_audio="host_sample.mp3",
chapter_markers=True, # 添加章节标记
background_music="soft", # 添加背景音乐
output_format="mp3"
)
print(f"有声内容已生成: {audio_file}")
视频配音与本地化
Spark-TTS的跨语言克隆功能使视频本地化变得简单高效,大幅降低了多语言内容制作的门槛。
案例分析:一家教育科技公司使用Spark-TTS将其英语教学视频批量转换为中文版本。通过采样原始英语讲师的声音,系统能够生成保留原讲师音色特点的中文配音。这种方法不仅保持了内容的连贯性和个人风格,还将本地化成本降低了70%,制作周期从传统的3周缩短至3天。
客户服务与企业应用
智能客服升级
Spark-TTS为智能客服系统提供了更自然、更具个性化的语音互动体验。
案例分析:某大型电商平台将Spark-TTS集成到其电话客服系统中,实现了千人千面的语音服务。系统会根据客户历史交互偏好,动态调整语音的语速、语调和风格,为不同年龄段和地区的用户提供最适合的交流体验。数据显示,这一升级使客户满意度提升了23%,平均通话时长减少17%,问题一次性解决率提高15%。
实现代码:
hljs python# 个性化客服语音生成
def generate_personalized_response(customer_id, response_text):
# 获取客户偏好数据
customer_prefs = get_customer_preferences(customer_id)
# 根据客户年龄调整语速
if customer_prefs['age'] > 60:
speed = 0.85 # 年长客户偏好较慢语速
elif customer_prefs['age'] < 30:
speed = 1.15 # 年轻客户偏好较快语速
else:
speed = 1.0
# 根据客户地区选择适合的声音模型
if customer_prefs['region'] == 'north':
voice_model = "northern_accent.wav"
else:
voice_model = "standard_accent.wav"
# 生成个性化语音响应
audio_response = tts_api.synthesize(
text=response_text,
reference_audio=voice_model,
speed=speed,
pitch=customer_prefs['preferred_pitch'],
emotion=get_appropriate_emotion(response_text)
)
return audio_response
企业培训与知识管理
Spark-TTS使企业内部培训和知识管理系统更加智能化和个性化。
案例分析:某跨国企业使用Spark-TTS构建了声音一致的内部培训系统。通过克隆资深培训师的声音,新的培训内容可以保持相同的语音风格,即使原培训师已离职或不可用。这不仅确保了培训体验的一致性,还使培训内容更新速度提升了3倍,每年节省培训制作成本约120万元。
无障碍与社会应用
个性化语音助手
Spark-TTS使得定制个人专属语音助手成为可能,特别是对有特殊需求的用户群体。
案例分析:一家健康科技公司开发了专为失语症患者设计的沟通辅助应用。该应用使用Spark-TTS克隆患者发病前的声音(通过家庭录像或语音记录),帮助他们使用自己原本的声音与他人交流。这一技术为患者带来了情感上的安慰和尊严,显著改善了生活质量和社交能力,被医疗专家评价为"心理恢复的重要辅助手段"。
教育个性化与包容性
Spark-TTS为教育领域带来了更具包容性和个性化的学习体验。
案例分析:某在线教育平台使用Spark-TTS为听障学生提供个性化学习内容。系统通过分析每个学生的学习进度和偏好,生成最适合其接受能力的语音教学内容,并根据学生的反馈实时调整语速和表达方式。这一系统使听障学生的学习效率提升了35%,课程完成率提高了42%。
创意与娱乐应用
游戏角色声音生成
Spark-TTS为游戏开发者提供了高效的角色配音解决方案。
案例分析:一家独立游戏工作室使用Spark-TTS为其角色扮演游戏生成超过100个NPC的配音。通过仅录制少量基础声音样本,再利用参数调整生成不同年龄、性格和情感状态的角色声音,大大丰富了游戏体验。这一方法将配音成本降低了85%,制作时间缩短了60%,同时提供了比传统方法更多样化的角色声音。
技术实现:
hljs python# 游戏角色声音生成系统
class NPCVoiceGenerator:
def __init__(self, api_key):
self.tts_api = SparkTTSAPI(api_key=api_key)
self.base_voices = {
"young_male": "base_young_male.wav",
"adult_male": "base_adult_male.wav",
"elder_male": "base_elder_male.wav",
"young_female": "base_young_female.wav",
"adult_female": "base_adult_female.wav",
"elder_female": "base_elder_female.wav"
}
def generate_character_voice(self, character_type, age, personality, dialogue):
# 选择基础声音
if "male" in character_type:
if age < 25:
base_voice = self.base_voices["young_male"]
elif age < 60:
base_voice = self.base_voices["adult_male"]
else:
base_voice = self.base_voices["elder_male"]
else:
if age < 25:
base_voice = self.base_voices["young_female"]
elif age < 60:
base_voice = self.base_voices["adult_female"]
else:
base_voice = self.base_voices["elder_female"]
# 根据性格调整参数
if personality == "cheerful":
pitch = 1.1
speed = 1.2
emotion = "happy"
elif personality == "serious":
pitch = 0.95
speed = 0.9
emotion = "serious"
elif personality == "mysterious":
pitch = 0.9
speed = 0.85
emotion = "mysterious"
else:
pitch = 1.0
speed = 1.0
emotion = "neutral"
# 生成角色语音
return self.tts_api.synthesize(
text=dialogue,
reference_audio=base_voice,
pitch=pitch,
speed=speed,
emotion=emotion
)
创意内容与艺术探索
Spark-TTS正在开启声音艺术与创意内容的新可能性。
案例分析:一位声音艺术家使用Spark-TTS创作了一件名为"千年回声"的艺术装置。艺术家收集了各个时代、不同地区人们的语音描述,然后使用AI技术将这些描述转换为统一的声音,创造出一种跨越时空的对话体验。该作品在国际媒体艺术展上获得了广泛关注,被评论家称为"AI与人文艺术结合的典范之作"。
常见问题与解决方案
在使用Spark-TTS的过程中,用户可能会遇到各种技术和应用问题。以下是最常见问题及其解决方案:
Q1: Spark-TTS对语音样本的质量和长度有什么要求?
A: Spark-TTS对语音样本的要求相对宽松,但遵循以下准则可获得最佳效果:
- 最低要求:清晰的3秒语音样本,无明显背景噪音
- 理想条件:10-30秒的语音样本,中等音量,自然语调
- 音频格式:最好使用16kHz或以上采样率的WAV或FLAC格式
- 内容建议:包含多种语调和情感变化的句子效果更好
如果样本质量不理想,可以使用预处理工具进行降噪和规范化,或尝试使用不同的语音片段。
Q2: 为什么生成的语音听起来不自然或有机械感?
A: 这可能由多种因素导致:
- 样本质量问题:参考样本本身可能有问题,尝试使用更高质量的样本
- 参数设置不当:语速或音调设置过高/过低会导致不自然感,尝试接近1.0的值
- 缺少情感标记:文本缺少适当的情感和停顿标记,尝试添加标点符号或SSML标记
- 模型限制:某些特殊语音特征可能超出模型能力范围
解决方案示例:
hljs python# 改进前
result = tts_api.synthesize("这是一段测试文本机械感较强", reference_audio="sample.wav")
# 改进后 - 添加停顿和情感变化
improved_text = "这是一段测试文本,(停顿0.3秒)语调更自然,感情更丰富。"
result = tts_api.synthesize(
improved_text,
reference_audio="sample.wav",
emotion="natural",
variation=0.2 # 添加微小随机变化,减少机械感
)
Q3: 跨语言声音克隆效果不佳怎么办?
A: 跨语言克隆是最具挑战性的应用场景之一,可以通过以下方法改善:
- 增加样本多样性:提供包含不同音素的多个样本
- 使用双语样本:如果可能,使用目标人物说目标语言的样本
- 保持语音风格:确保源语言和目标语言具有相似的语速和风格
- 微调发音参数:针对特定语言对发音参数进行微调
最佳实践是提供至少30秒的高质量语音样本,并进行多次测试调整。
Q4: 如何处理超长文本的合成问题?
A: 超长文本合成可能面临内存不足或质量不一致的问题,建议:
- 分段处理:将长文本分成较小的段落(500-1000字)单独处理
- 保持上下文:确保分段点在自然的句子或段落边界
- 统一参数:对所有段落使用相同的语音参数和参考样本
- 后期处理:使用音频编辑工具无缝连接各段落,调整音量一致性
使用laozhang.ai的批处理API可以自动处理这一过程:
hljs pythonresult = tts_api.batch_synthesize(
long_text=article_text,
reference_audio="narrator.wav",
chunk_size=500, # 每段文字长度
overlap=50, # 重叠部分长度(保证平滑过渡)
auto_merge=True # 自动合并音频片段
)
Q5: CPU使用Spark-TTS速度太慢,有什么解决方案?
A: 在CPU环境下Spark-TTS确实会面临性能瓶颈,可以考虑:
- 优化批处理:一次性处理多个文本,而不是逐条处理
- 降低精度:使用半精度(FP16)或混合精度模式
- 简化模型:使用较小的模型变体(如果有)
- 使用API服务:对于大规模需求,使用laozhang.ai等云服务是最经济的解决方案
对于生产环境,强烈推荐使用API服务或配备GPU的环境。
Q6: 如何解决声音克隆的伦理和法律问题?
A: 声音克隆技术确实带来了伦理和法律考量:
- 获取同意:在克隆他人声音前获得明确授权
- 透明使用:清晰标示AI生成的内容
- 防止滥用:实施安全措施防止欺诈或冒充
- 遵守法规:了解并遵守所在地区关于声音权利的法律
laozhang.ai API服务已经实施了多层安全措施,并要求用户承诺合法使用。
伦理使用提醒
声音克隆技术应当用于积极、创造性的目的,而非欺骗或冒充他人。请在使用Spark-TTS等声音克隆技术时,始终保持透明度并获得必要授权。
Q7: 生成的语音文件大小过大,如何优化?
A: 语音文件大小优化的几种方法:
- 选择高效格式:使用Opus或AAC格式代替WAV可减少70-80%的文件大小
- 调整采样率:对于大多数应用,16kHz采样率足够清晰
- 使用压缩:应用适当的音频压缩,平衡质量和大小
- 移除静音:自动检测并移除过长的静音段落
hljs python# 优化音频文件大小
optimized_audio = tts_api.synthesize(
text=text,
reference_audio="sample.wav",
output_format="opus", # 高效压缩格式
sample_rate=16000, # 降低采样率
remove_silence=True, # 移除多余静音
bit_rate="64k" # 控制比特率
)
Q8: 如何确保不同批次生成的语音保持一致性?
A: 保持语音一致性的关键措施:
- 保存声音嵌入:提取并保存参考声音的嵌入向量,而不是每次重新提取
- 固定随机种子:设置固定的随机种子确保结果可重复
- 标准化参数:为所有批次使用相同的语速、音调等参数
- 使用版本控制:记录使用的确切模型版本和参数配置
hljs python# 提取并保存声音嵌入
speaker_embedding = tts_api.extract_speaker_embedding("sample.wav")
with open("speaker_embedding.pkl", "wb") as f:
pickle.dump(speaker_embedding, f)
# 后续使用保存的嵌入
with open("speaker_embedding.pkl", "rb") as f:
speaker_embedding = pickle.load(f)
# 使用相同嵌入生成多个音频
for text in text_list:
audio = tts_api.synthesize(
text=text,
speaker_embedding=speaker_embedding, # 使用保存的嵌入
seed=42, # 固定随机种子
# 其他参数保持一致
)
未来展望与结论
随着Spark-TTS技术的迅速发展和广泛应用,我们站在AI语音合成技术的新拐点。本节将探讨这一领域的未来发展趋势,以及如何为即将到来的变革做好准备。
Spark-TTS的未来发展方向
1. 多模态融合
未来的Spark-TTS将不仅限于音频维度,而是向多模态方向扩展:
- 音视频协同生成:同步生成匹配的口型动画和面部表情
- 情感与姿态结合:根据语音内容自动生成配套的肢体语言和表情
- 跨感官体验:将语音与触觉、视觉等其他感官信息协同生成
技术预测:到2026年,Spark-TTS有望整合视频生成技术,实现单一API调用同时生成音频和匹配的视频内容,为虚拟主播和数字人带来革命性变化。
2. 超个性化与情感深度
当前版本的Spark-TTS已具备基础情感表达,但未来版本将大幅提升这一能力:
- 微表情捕捉:捕获和复制人类语音中的微妙情感变化
- 性格模拟:模拟特定人物的说话习惯、停顿和语气特点
- 情境适应:根据内容自动调整情感表达的强度和类型
研究动向:SparkAudio研究团队已经展示了prototype版本,能够从短短5秒的样本中提取超过120种语音特征参数,实现前所未有的个性化还原度。
3. 极致效率与轻量化
随着边缘计算和移动设备的普及,Spark-TTS将朝着更高效和轻量化方向发展:
- 模型压缩:在保持质量的同时,大幅减小模型体积
- 硬件优化:针对ARM、移动GPU等平台的专门优化
- 增量学习:支持在设备端进行轻量级的个性化微调
产业趋势:预计2026年将出现专用的语音合成硬件加速器,类似于NPU,专门针对TTS任务优化,将功耗降低90%,速度提升5-10倍。
4. 交互式生成与实时控制
未来的Spark-TTS将实现更自然的人机交互模式:
- 实时声音转换:即时将用户声音转换为目标声音
- 互动式调整:通过简单语音指令调整输出效果
- 上下文感知生成:基于对话历史自动调整语调和情感
应用前景:这将开启真正自然的AI助手时代,用户可以说"用更兴奋的语气再说一遍",AI将立即调整语音表现。
对开发者和企业的建议
战略布局建议
针对不同规模和需求的组织,我们提供以下策略建议:
初创企业与个人开发者:
- 专注于特定垂直领域,如教育或内容创作,构建基于Spark-TTS的差异化应用
- 利用API服务快速验证产品概念,成熟后再考虑自建基础设施
- 积极关注开源社区动态,合理利用和贡献代码
中小企业:
- 采用混合策略,关键业务使用API服务保证稳定性,同时通过本地部署探索创新应用
- 投资内容和声音资产库,建立企业专属的声音标识
- 关注用户隐私和数据安全,确保合规使用
大型企业与机构:
- 建立专门的语音合成团队,结合云服务和本地部署构建混合架构
- 投资声音数字资产管理,将声音视为品牌资产的重要组成部分
- 参与开源社区和标准制定,引领行业发展方向
技术准备路线图
为未来的Spark-TTS发展做好技术准备,开发者可以遵循以下路线图:
-
基础设施准备:
- 规划弹性的计算资源架构,能够根据需求扩展
- 设计模块化的音频处理管道,便于集成新功能
- 建立声音资产管理系统,包括参考样本库和嵌入向量库
-
能力建设:
- 培养跨学科团队,覆盖语音处理、机器学习和用户体验设计
- 开发声音质量评估体系,建立客观和主观评价标准
- 积累特定领域的语音语料和知识库
-
应用创新:
- 探索与其他AI技术的融合应用,如语音+图像、语音+对话
- 开发行业特定的语音解决方案,满足专业场景需求
- 关注用户反馈,持续迭代改进语音体验
展望与结语
Spark-TTS作为开源声音克隆和语音合成领域的重要创新,正在重塑我们与数字世界交互的方式。从内容创作到客户服务,从无障碍应用到娱乐体验,这项技术的影响力将持续扩大。
随着技术的不断进步,我们有理由相信,未来的语音交互将变得更加自然、个性化和情感丰富。通过零样本声音克隆能力,每个个体的声音特征都可以被数字化保存和重现,为人与机器的互动增添前所未有的温度和情感维度。
对于开发者和企业而言,现在正是探索和应用这一技术的黄金时期。无论是通过laozhang.ai提供的高性能API服务快速集成,还是通过开源代码进行深度定制,Spark-TTS都提供了宝贵的机会,让您在新一代语音交互革命中抢占先机。
🚀 立即行动
准备好踏上Spark-TTS的探索之旅了吗?立即访问laozhang.ai注册账户,获取免费API额度,体验AI语音克隆的魅力!国内首家提供Spark-TTS专业API服务,无需复杂环境配置,即刻开始创造令人惊叹的声音体验!
最后更新: 2025年4月10日
免责声明: 本文介绍的技术仅供学习和合法使用。使用Spark-TTS进行声音克隆时,请确保获得相关授权并遵守所在地区的法律法规。不当使用可能导致法律风险和伦理问题。