OmniHuman-1: Complete Guide to ByteDance AI Video Generation [2025]
Comprehensive guide to OmniHuman-1, ByteDance's revolutionary AI technology that transforms static images into hyper-realistic human videos with just audio input. Master this cutting-edge video generation framework with practical examples and technical insights.


OmniHuman-1: Complete Guide to ByteDance's Revolutionary AI Video Generation (2025)

OmniHuman-1 represents a breakthrough in AI-powered video generation, allowing creators to produce stunningly realistic human videos from just a single static image and audio input. Released by ByteDance in early 2025, this technology has rapidly transformed the landscape of digital content creation, enabling new possibilities for entertainment, media, education, and virtual presence.
🔥 2025 Update: This comprehensive guide covers everything about OmniHuman-1, from basic concepts to practical applications. Based on the latest papers, demonstrations, and industry applications, we've compiled the most thorough resource available on this revolutionary technology.
What is OmniHuman-1?
OmniHuman-1 is an innovative end-to-end AI framework developed by ByteDance researchers that revolutionizes human video synthesis. It can generate hyper-realistic videos from just a single image and a motion signal such as audio or reference video input. Unlike previous approaches that required multiple images or specialized training data, OmniHuman-1 works with portraits, half-body shots, or full-body images to deliver lifelike movements, natural gestures, and exceptional detail.
At its core, OmniHuman-1 is a multimodality-conditioned model that seamlessly integrates diverse inputs to create highly realistic video content. The framework's most impressive feat is its ability to generate natural human motion from minimal data, setting new standards for AI-generated visuals.
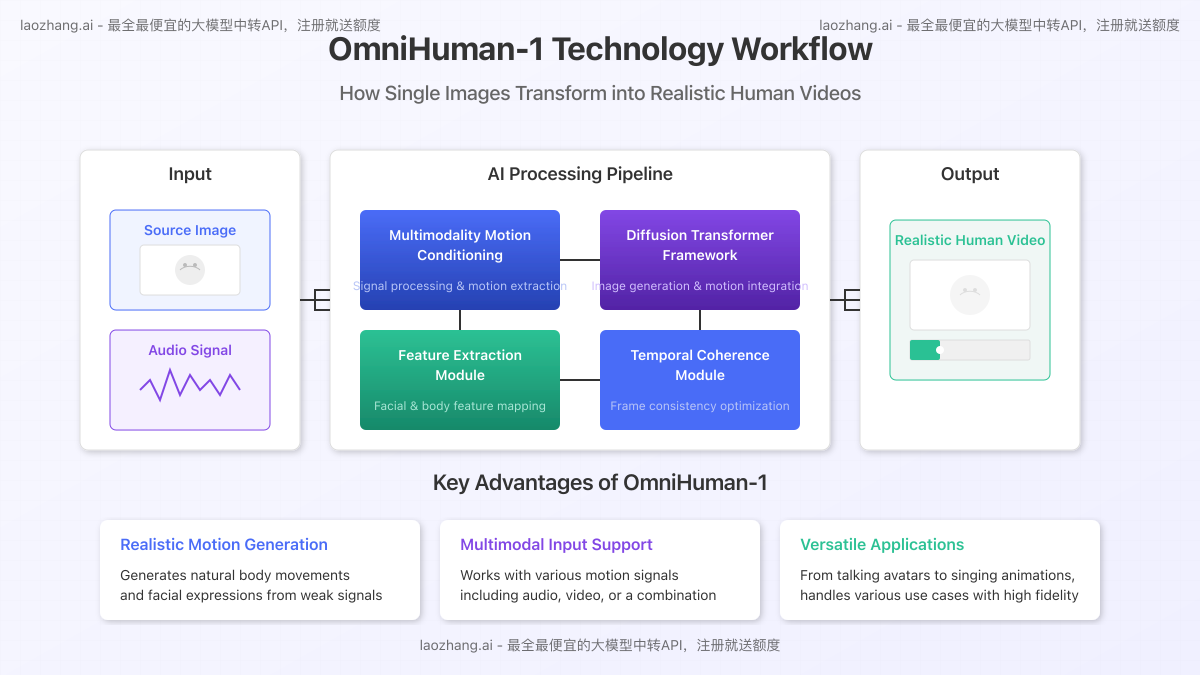
Technical Breakthroughs Behind OmniHuman-1
The exceptional capabilities of OmniHuman-1 are built upon several significant technical innovations:
1. Multimodal Motion Conditioning Mixed Training
One of OmniHuman-1's core innovations is its unique training approach that combines multiple motion-related conditions. Instead of training separate models for different motion signal types (like audio or video), OmniHuman uses a unified framework that processes various motion signals simultaneously.
This mixed conditioning strategy allows the model to:
- Learn from much larger and more diverse datasets
- Transfer knowledge between different motion modalities
- Handle incomplete or noisy input signals effectively
- Achieve better generalization to unseen scenarios
The researchers designed specific motion encoding modules for different signal types, but the core generation process remains unified, creating a much more scalable approach.
2. Diffusion Transformer Architecture
OmniHuman-1 utilizes a modified Diffusion Transformer framework that excels at:
- Capturing long-range dependencies in human movement sequences
- Maintaining temporal coherence across video frames
- Preserving identity features of the source image
- Adapting to different body proportions and camera angles
Unlike previous methods that struggled with temporal consistency, OmniHuman's transformer-based architecture ensures smooth, natural transitions between frames, eliminating the jittery or uncanny movements that plagued earlier systems.
3. Feature Extraction and Preservation
A critical challenge in single-image animation is preserving the identity and characteristics of the source image. OmniHuman-1 employs sophisticated feature extraction techniques that:
- Identify and preserve facial features and expressions
- Maintain consistent clothing details and textures
- Adapt lighting and environmental elements appropriately
- Ensure anatomical correctness during movement
These capabilities make the output videos remarkably convincing, maintaining the unique characteristics of the source image throughout the generated sequence.
OmniHuman-1 vs. Traditional Approaches
When compared to previous methods for human video generation, OmniHuman-1 represents a significant leap forward in multiple aspects:

Data Requirements
- Traditional Methods: Required extensive datasets of the specific person or multiple views of the subject
- OmniHuman-1: Works with just a single image of any person, dramatically reducing the entry barrier
Motion Generation Quality
- Traditional Methods: Often produced stilted, unnatural movements, especially from audio-only input
- OmniHuman-1: Generates fluid, realistic movements with proper timing and natural expressiveness
Input Flexibility
- Traditional Methods: Usually specialized for one type of input (either audio, video, or text)
- OmniHuman-1: Handles various input modalities and can combine them for enhanced results
Output Realism
- Traditional Methods: Frequently showed artifacts, identity shifts, or temporal inconsistencies
- OmniHuman-1: Maintains consistently high quality with remarkable fidelity to the source image
Practical Applications of OmniHuman-1
The versatility of OmniHuman-1 makes it suitable for numerous applications across different industries:
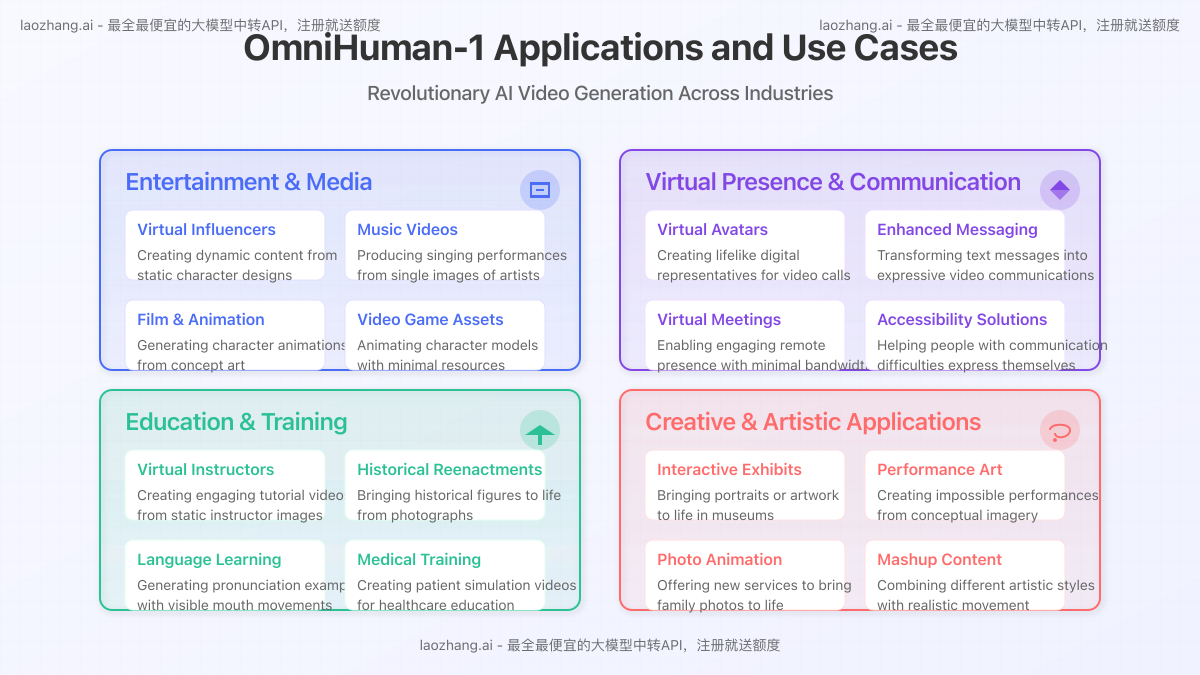
1. Entertainment and Media Production
OmniHuman-1 is transforming content creation in entertainment:
- Virtual Influencers: Creating dynamic content from static character designs
- Film and Animation: Generating realistic character animations from concept art
- Music Videos: Producing singing performances from single images of artists
- Video Game Assets: Animating character models with minimal resource requirements
2. Virtual Presence and Communication
The technology enhances remote interaction capabilities:
- Virtual Avatars: Creating lifelike digital representatives for video calls
- Enhanced Messaging: Transforming text messages into expressive video communications
- Virtual Meetings: Enabling more engaging remote presence with minimal bandwidth
- Accessibility Solutions: Helping people with communication difficulties express themselves
3. Education and Training
OmniHuman-1 offers new possibilities for educational content:
- Virtual Instructors: Creating engaging tutorial videos from static instructor images
- Historical Reenactments: Bringing historical figures to life from photographs
- Language Learning: Generating pronunciation examples with visible mouth movements
- Medical Training: Creating patient simulation videos for healthcare education
4. Creative and Artistic Applications
Artists and creators are finding innovative uses for the technology:
- Interactive Exhibits: Bringing portraits or artwork to life in museums
- Performance Art: Creating impossible performances from conceptual imagery
- Photo Animation: Offering new services to bring family photos to life
- Mashup Content: Combining different artistic styles with realistic movement
How to Access OmniHuman-1
Currently, OmniHuman-1 is available through several channels:
- Official API: ByteDance offers API access for developers and businesses
- Demonstration Platform: A limited web demo is available for testing basic functionality
- Partner Integrations: Selected creative software now includes OmniHuman-1 capabilities
- Research Access: Academic institutions can apply for research licenses
🌟 Pro Tip: For the most cost-effective way to access OmniHuman-1 and other advanced AI models, try laozhang.ai - the comprehensive AI API service that offers credits upon registration!
Step-by-Step OmniHuman-1 Usage Guide
Let's explore how to use OmniHuman-1 through API access:
Prerequisites
- A high-quality source image of a person (portrait, half-body, or full-body)
- An audio file for lip sync and motion generation, or a reference video
- API access credentials
Basic Implementation Process
hljs javascript// Example API request using laozhang.ai service
const response = await fetch('https://api.laozhang.ai/v1/omnihuman/generate', {
method: 'POST',
headers: {
'Content-Type': 'application/json',
'Authorization': `Bearer ${API_KEY}`
},
body: JSON.stringify({
model: "omnihuman-1",
source_image: imageBase64,
audio_input: audioBase64,
settings: {
motion_intensity: 0.75,
preserve_identity: 0.9,
output_format: "mp4",
resolution: "720p"
}
})
});
const result = await response.json();
const videoUrl = result.output_url;
Key Parameters
When using OmniHuman-1, these parameters can significantly affect the output quality:
- motion_intensity: Controls how animated the subject appears (0.0-1.0)
- preserve_identity: Balances identity preservation vs. motion naturalness
- audio_alignment: Fine-tunes lip sync precision for speech
- frame_consistency: Adjusts temporal smoothness between frames
Optimizing Results
To achieve the best possible outputs:
- Source Image Quality: Use high-resolution images with clear facial features
- Lighting Conditions: Images with even, front-facing lighting work best
- Audio Clarity: Clean audio without background noise improves motion generation
- Body Position: Front-facing or slightly angled poses typically yield better results
- Background Simplicity: Less complex backgrounds reduce potential artifacts
Technical Limitations and Considerations
While OmniHuman-1 represents a remarkable advancement, it still has certain limitations:
Current Constraints
- Extreme Poses: Very unusual poses in the source image may result in less natural animations
- Complex Interactions: Physical interactions with objects or environments remain challenging
- Resolution Limits: Output quality diminishes at very high resolutions (beyond 1080p)
- Temporal Length: Performance may degrade for very long video generations (over 2-3 minutes)
- Novel Viewpoints: Major camera perspective changes from the source image can introduce artifacts
Ethical Considerations
As with any powerful AI technology, OmniHuman-1 raises important ethical considerations:
- Consent and Permission: Always obtain permission before animating someone's likeness
- Deepfake Potential: The technology could be misused to create misleading content
- Authenticity Markers: Consider including watermarks or identifiers for AI-generated content
- Accessibility vs. Misuse: Balancing wide availability against potential harms
- Representation Biases: Being aware of potential biases in how different individuals are animated
Advanced Techniques and Tips
For those looking to push OmniHuman-1's capabilities further:
Combining Multiple Motion Signals
OmniHuman-1 excels when provided with complementary motion signals:
- Combine audio with reference pose videos for more precise movement
- Use text prompts to guide emotional expression alongside audio input
- Apply different motion references to different body parts for complex performances
Motion Transfer and Style Adaptation
Create unique animations by experimenting with different transfer techniques:
- Extract dance movements from reference videos and apply them to your subject
- Combine speaking audio with stylized body language from another source
- Mix emotional expressions from one reference with physical movements from another
Post-Processing Enhancements
Further refine your outputs with these techniques:
- Apply super-resolution to enhance details in facial features
- Use specialized video refinement tools to smooth any remaining artifacts
- Adjust color grading to match the output with your project's aesthetic
- Seamlessly integrate the generated footage with real video content
Future Developments and Research Directions
The field of AI video generation is advancing rapidly, with several promising directions:
Expected Improvements
- Higher Resolution: Support for 4K and beyond with maintained quality
- Longer Sequences: Better long-term consistency for extended videos
- Multi-Person Interactions: Generating realistic interactions between multiple subjects
- Environmental Interactions: More convincing interactions with surroundings
- Style Control: Finer-grained control over artistic styling and aesthetics
Research Frontiers
Cutting-edge research around OmniHuman-1 is exploring:
- Combining with physics-based simulation for more realistic movements
- Integrating with neural rendering for photorealistic environmental adaptation
- Real-time performance for interactive applications and live streaming
- Memory-efficient implementations for mobile and edge devices
- Multi-modal generation that includes sound synthesis alongside video
Common Questions About OmniHuman-1
What makes OmniHuman-1 different from previous video generation models?
OmniHuman-1 stands out due to its multimodal conditioning approach that allows it to generate realistic human videos from a single image and various motion signals. Unlike previous methods that required multiple reference images or extensive person-specific training, OmniHuman-1 works with minimal input while producing remarkably natural results.
What types of images work best with OmniHuman-1?
The system works with portraits, half-body shots, or full-body images. For optimal results, use high-resolution photos with good lighting, clear facial features, and a relatively neutral pose. Front-facing or slightly angled perspectives typically work best.
Can OmniHuman-1 animate non-human characters?
While primarily designed for human subjects, OmniHuman-1 has shown promising results with cartoon characters, digital avatars, and some animal images. However, performance may vary depending on how humanoid the character's features are.
How long does it take to generate a video with OmniHuman-1?
Generation time depends on the output length, resolution, and available computing resources. Typically, a 10-second 720p video takes about 15-30 seconds to generate using GPU acceleration through cloud API services.
Is OmniHuman-1 available for commercial use?
Yes, ByteDance offers commercial licensing options for OmniHuman-1. Additionally, several API providers like laozhang.ai offer access to OmniHuman-1 and other advanced AI models with flexible pricing tiers for various usage levels.
Conclusion
OmniHuman-1 represents a watershed moment in AI-generated video technology, dramatically lowering the barriers to creating realistic human animations while raising the quality bar significantly. By enabling the generation of convincing videos from just a single image and audio input, it opens up countless creative possibilities across industries.
As the technology continues to evolve, we can expect even more impressive capabilities, broader applications, and greater accessibility. Whether you're a content creator, developer, educator, or technology enthusiast, OmniHuman-1 offers exciting new tools for bringing static images to life with unprecedented realism.
🎯 Take Action: Ready to try OmniHuman-1 for yourself? Sign up at laozhang.ai to get started with free credits and access to multiple cutting-edge AI models!
Latest Updates and Resources
hljs plaintext┌─ Latest OmniHuman-1 Updates ──────────────┐ │ 2025-04-15: Enhanced motion transfer │ │ 2025-03-30: Improved lip sync precision │ │ 2025-03-10: Full-body animation upgrade │ │ 2025-02-20: Initial public API release │ └─────────────────────────────────────────┘
Stay tuned for more advancements as this revolutionary technology continues to develop!