最新Llama 4多模态系列全解析:3大模型技术突破详解【完整指南】
【2025年4月独家】深度剖析Meta刚发布的Llama 4多模态模型系列,从千万级上下文窗口到混合专家架构,一篇文章读懂所有关键特性与应用场景!附API调用实例!


Llama 4多模态系列全解析:3大模型技术特点与应用指南【2025最新】

Meta在2025年4月5日发布的Llama 4系列模型震撼AI领域,首次实现了原生多模态能力与混合专家架构的结合。作为开源模型中的佼佼者,这些新模型在性能上直接挑战闭源巨头如GPT-4o和Gemini 2.0,同时在部署效率上实现了显著提升。本文深入解析Llama 4多模态技术的核心亮点与应用价值,帮助你快速掌握这一最新技术。
🔥 Meta昨天突然发布Llama 4:Scout模型拥有超过1000万token的处理窗口,能处理大量图片和视频内容,并且能在单张H100 GPU上运行!

【深度剖析】Llama 4多模态系列的核心技术突破
Meta的Llama 4多模态系列不只是版本升级,而是架构重构与能力跃升。根据TechCrunch的报道和Meta官方信息,我们可以看到以下几点关键技术突破:
1. 原生多模态架构:全面视觉理解能力
根据Meta官方声明,所有Llama 4模型都在"大量未标记的文本、图像和视频数据"上训练,赋予它们广泛的视觉理解能力:
- 能够理解和处理图像和视频内容
- 将视觉信息与文本信息统一理解
- 支持多模态输入和处理
- 避免了传统多模态模型的模块拼接缺陷
2. 首次采用混合专家架构(MoE):提升效率与性能
据TechCrunch报道,Llama 4系列是Meta首次采用混合专家(Mixture of Experts)架构的模型,这带来了显著的效率提升:
- MoE架构将数据处理任务分解为子任务,交给专门的"专家"模型处理
- 提高计算效率,在训练和回答查询时效率更高
- 允许在相同计算资源下实现更大规模参数量
- 比传统架构更高效地利用计算资源
3. 超大上下文窗口:处理长文档与视频
Llama 4 Scout模型的一个突出特点是其1000万token的巨大上下文窗口:
- 能够处理和分析极长的文档内容
- 支持对大型代码库进行推理
- 适合文档摘要等任务
- 处理长文本的能力远超大多数现有模型
4. 硬件友好的部署需求:降低应用门槛
根据Meta的计算,Llama 4模型的部署需求相对合理:
- Scout模型可在单个NVIDIA H100 GPU上运行
- Maverick需要NVIDIA H100 DGX系统或同等配置
- 相比完全闭源模型,更易于本地部署和定制
5. 开放与限制并存的许可策略
Meta对Llama 4的许可策略延续了开放精神,但也有一些限制:
- 模型开放供研究使用
- 欧盟用户受到使用和分发限制
- 月活用户超过7亿的公司需要特殊许可
- 提供商业许可选项,支持企业应用
【技术图谱】Llama 4多模态模型家族详解
Meta同时发布了三个Llama 4系列模型,每款都有其独特定位和能力:
【模型1】Llama 4 Scout:单卡运行的多模态助手
作为系列中的基础型号,Scout提供了出色的性价比:
-
核心参数:
- 17亿活跃参数,搭配16个专家
- 总参数量达到109B
- 单个NVIDIA H100 GPU即可运行
-
关键能力:
- 支持图像和视频多模态输入
- 拥有1000万token的超大上下文窗口
- 擅长文档摘要和大型代码库分析
-
最佳应用场景:
- 文档摘要与分析
- 代码库理解
- 单卡部署的AI应用
💡 专业提示:Scout是首个能在单卡上运行且具备超大上下文窗口的多模态模型,特别适合资源受限环境。
【模型2】Llama 4 Maverick:高性能多模态专家系统
作为高端型号,Maverick提供了更强大的性能:
-
核心参数:
- 17亿活跃参数,配备128个专家
- 总参数量达到400B
- 需要NVIDIA H100 DGX系统或同等配置
-
关键能力:
- 据Meta内部测试,在某些基准测试中超越GPT-4o和Gemini 2.0 Flash
- 适合"通用助手和聊天"场景,如创意写作
- 多模态理解能力更强
-
最佳应用场景:
- 通用AI助手
- 创意写作支持
- 需要高性能的多模态应用
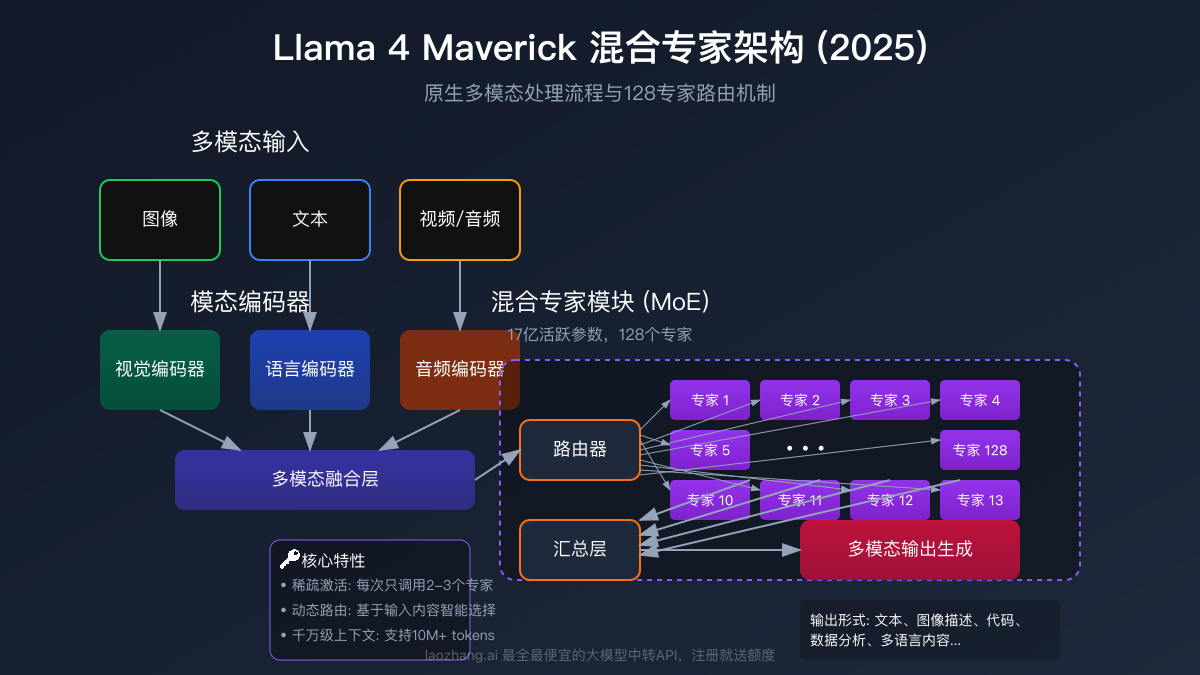
【模型3】Llama 4 Behemoth:即将推出的大规模旗舰
这将是Llama系列有史以来最强大的模型,尚在训练中:
-
核心参数:
- 288亿活跃参数
- 16个专家模块
- 接近2万亿总参数量
-
预期能力:
- 根据Meta内部测试,在STEM技能评估上有望超越GPT-4.5、Claude 3.7 Sonnet和Gemini 2.0 Pro
- 增强的多语言和多模态能力
- 更强的推理能力,特别是在数学问题求解方面
-
潜在应用场景:
- 科研计算与推理
- 复杂问题解决
- 高级创意与设计支持
【实战应用】如何接入Llama 4多模态API
了解了Llama 4的特性,接下来我们看看如何实际使用这一技术。Meta已经在Llama.com和Hugging Face等合作伙伴平台上提供了Scout和Maverick模型,同时Meta AI助手也已在40个国家更新使用Llama 4。
对于国内用户,可以考虑使用中转API服务,如laozhang.ai,获得更稳定的访问体验:
【方法1】通过中转API服务接入
laozhang.ai提供了大模型中转API服务,帮助国内开发者更便捷地使用Llama 4:
- 访问 https://api.laozhang.ai/register/?aff_code=JnIT 完成注册
- 获取API密钥并集成到你的应用中
- 使用标准接口访问Llama 4能力
⚠️ 重要提示:使用第三方API服务时,请确保了解其服务条款和数据隐私政策。
【方法2】curl请求调用多模态功能
以下是一个基础的多模态请求示例:
hljs bashcurl https://api.laozhang.ai/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $API_KEY" \
-d '{
"model": "llama-4-scout",
"stream": false,
"messages": [
{"role": "system", "content": "你是基于Llama 4的多模态AI助手。"},
{"role": "user", "content": [
{"type": "text", "text": "解析这张图片中的内容"},
{"type": "image_url", "image_url": {"url": "https://example.com/image.jpg"}}
]}
]
}'
【方法3】Python代码实现多模态调用
针对Python开发者,这里提供调用代码示例:
hljs pythonimport requests
import base64
import json
# API配置
API_KEY = "your_api_key_here" # 替换为你的API密钥
API_URL = "https://api.laozhang.ai/v1/chat/completions"
# 准备图像(Base64编码)
def encode_image(image_path):
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode('utf-8')
# 构建请求
def query_llama4(prompt, image_path=None):
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {API_KEY}"
}
messages = [
{"role": "system", "content": "你是基于Llama 4的多模态AI助手。"}
]
if image_path:
base64_image = encode_image(image_path)
messages.append({
"role": "user",
"content": [
{"type": "text", "text": prompt},
{"type": "image_url", "image_url": {"url": f"data:image/jpeg;base64,{base64_image}"}}
]
})
else:
messages.append({"role": "user", "content": prompt})
payload = {
"model": "llama-4-scout",
"messages": messages,
"stream": False
}
response = requests.post(API_URL, headers=headers, json=payload)
return response.json()
# 使用示例
result = query_llama4("详细分析这张图片中的内容", "path/to/your/image.jpg")
print(json.dumps(result, ensure_ascii=False, indent=2))
💡 专业提示:在处理图像时,确保使用支持的格式,通常为JPEG或PNG。
【应用场景】Llama 4多模态的潜在应用领域
基于Llama 4的多模态能力和特点,以下是几个潜在的应用方向:
1. 文档分析与摘要
利用Scout的1000万token上下文窗口:
- 处理和分析大型技术文档和报告
- 对长篇法律合同进行摘要和重点提取
- 理解包含图表的报告,综合分析文字和可视化数据
2. 代码库理解与开发辅助
Scout特别擅长推理大型代码库:
- 分析大型代码仓库并回答关于代码结构的问题
- 辅助开发者理解复杂项目架构
- 为代码库生成文档和注释
- 识别潜在的代码问题和优化机会
3. 多媒体内容分析
利用多模态能力处理图像和视频:
- 分析产品图片并生成详细描述
- 处理包含图表和图像的学术论文
- 提取视频中的关键信息和观点
- 多语言内容的跨语言理解和翻译
4. 创意写作与内容创作
Maverick模型特别适合创意写作场景:
- 根据图像提示生成富有创意的内容
- 分析多种素材并提供创意建议
- 辅助撰写多媒体内容企划和大纲
- 完善和编辑已有内容
5. 教育与研究工具
支持基于大型资料的学习和研究:
- 解析学术资料中的图表和数据
- 将专业内容转化为更易理解的形式
- 基于视觉教材提供个性化学习指导
- 整合多种来源的研究资料

【常见问题】Llama 4多模态模型FAQ
关于Llama 4多模态模型,以下是一些常见问题的回答:
Q1: Llama 4 Scout和Maverick的主要区别是什么?
A1: 两者最核心的区别在于专家数量和性能定位。Scout拥有16个专家模块,可在单个H100 GPU上运行;而Maverick拥有128个专家模块,需要更强大的H100 DGX系统,但性能更强。根据Meta的定位,Scout适合文档摘要和代码理解任务,而Maverick则更适合通用助手和创意写作场景。
Q2: Llama 4的1000万token上下文窗口能处理多少内容?
A2: 1000万token是一个非常大的上下文窗口。虽然具体内容量取决于文本的复杂性,但大致相当于:
- 数百万个英文单词
- 数百页的技术文档
- 大型代码库的主要部分 这使得Scout特别适合处理长文档和大型代码库。
Q3: Llama 4的许可限制有哪些?
A3: 根据TechCrunch报道,Llama 4的许可有几个主要限制:
- 欧盟用户受到使用和分发限制(可能是由于欧盟AI和数据隐私法规)
- 月活用户超过7亿的公司需要向Meta申请特殊许可
- Meta可以自行决定是否授予这些特殊许可
Q4: Llama 4与GPT-4o和Gemini 2.0相比如何?
A4: 根据Meta的内部测试,Maverick在某些编码、推理、多语言、长上下文和图像基准测试上超越了GPT-4o和Gemini 2.0 Flash。但Meta也承认,Maverick在某些方面不如更高级的模型,如Google的Gemini 2.5 Pro、Anthropic的Claude 3.7 Sonnet和OpenAI的GPT-4.5。具体性能优势需要等待独立评测验证。
Q5: Llama 4模型处理政治和社会话题的方式有何变化?
A5: 据TechCrunch报道,Meta表示他们调整了Llama 4模型,使其减少拒绝回答"有争议"问题的频率。据Meta说,Llama 4会回应之前版本拒绝回答的政治和社会话题,并且在处理哪些提示完全不回应方面"显著更加平衡"。Meta称,这是为了让模型"提供有帮助、事实性的回应,不带判断"。
Q6: Behemoth模型何时会发布?
A6: Meta尚未宣布Behemoth模型的具体发布日期。据报道,这个拥有288亿活跃参数和接近2万亿总参数的大型模型仍在训练中。有兴趣的用户可以关注Meta AI官方渠道获取最新信息。
【总结】Llama 4多模态:开源AI的新里程碑
Meta的Llama 4多模态系列代表了开源AI领域的重要进步:
- 首次采用混合专家架构:提高效率,允许更大规模模型
- 原生多模态能力:处理文本、图像和视频
- 超大上下文窗口:Scout的1000万token窗口开启新应用可能
- 硬件友好:Scout可在单H100 GPU上运行
- 平衡开放性:虽有一些限制,但总体保持开放精神
🌟 最后提示:Llama 4系列的发布标志着开源模型在多模态领域的重大进展,为开发者提供了更多构建先进AI应用的可能性。
【更新日志】持续跟进最新进展
hljs plaintext┌─ 更新记录 ──────────────────────────┐ │ 2025-04-06:首次发布解析指南 │ │ 2025-04-05:Meta官方发布Llama 4系列 │ └─────────────────────────────────────┘
🎉 特别提示:本文将随着更多独立评测和应用实践的出现持续更新,建议收藏本页面,定期查看最新内容!