2025最新GPT-4o-mini-search-preview使用指南:OpenAI联网搜索模型完全攻略
【独家揭秘】OpenAI最新联网搜索模型GPT-4o-mini-search-preview全面解析!功能特点、API接入、应用场景一网打尽,附带实用代码示例和优化技巧,让你10分钟掌握AI联网搜索新能力!


GPT-4o-mini-search-preview使用指南:OpenAI联网搜索模型详解【2025最新】

OpenAI近日突然发布了两款专门针对网络搜索优化的模型:GPT-4o-search-preview和GPT-4o-mini-search-preview,这标志着AI辅助搜索功能正式向开发者开放API接口。本文将深入解析其中更为轻量且高性价比的GPT-4o-mini-search-preview模型,从功能特点、应用场景到接入方法,为开发者提供一站式指南。
🔥 2025年4月最新:OpenAI刚刚在4月初推出这款联网搜索专用模型,本文提供第一手实测体验与完整API调用示例,助你快速掌握这一新功能!

【模型解析】什么是GPT-4o-mini-search-preview?核心技术揭秘
GPT-4o-mini-search-preview是OpenAI专门为网络搜索场景优化的AI模型,它基于GPT-4o-mini架构,但经过了特殊训练,能够更好地理解和执行Web搜索查询。与常规模型相比,它具有以下显著特点:
1. 搜索意图理解:精准捕捉用户搜索需求
这款模型最核心的能力是对搜索意图的深度理解。它能够:
- 准确识别查询中的核心关键词和实体
- 理解复杂、多步骤的搜索需求
- 区分信息型、导航型和交易型搜索意图
- 自动优化搜索词,提高搜索效率
2. 网络知识获取:实时联网能力加持
与传统模型依赖训练数据不同,GPT-4o-mini-search-preview可以:
- 通过API直接获取最新的网络信息
- 处理和综合多个搜索结果
- 提取网页内容中的关键信息
- 识别并引用可靠的信息来源
3. 结果优化处理:信息聚合与去重
这款模型在处理搜索结果方面表现出色:
- 自动过滤低质量或重复内容
- 综合多来源信息提供全面回答
- 对搜索结果进行结构化整理
- 突出显示最相关和权威的信息
4. 轻量级设计:性能与成本平衡
作为"mini"版本,该模型在保持核心搜索能力的同时:
- 响应速度更快,适合实时交互
- API调用成本显著低于GPT-4o-search-preview
- 资源消耗更少,适合大规模部署
- 在回答简单查询时表现接近完整版
【实战指南】如何接入GPT-4o-mini-search-preview?完整API调用流程
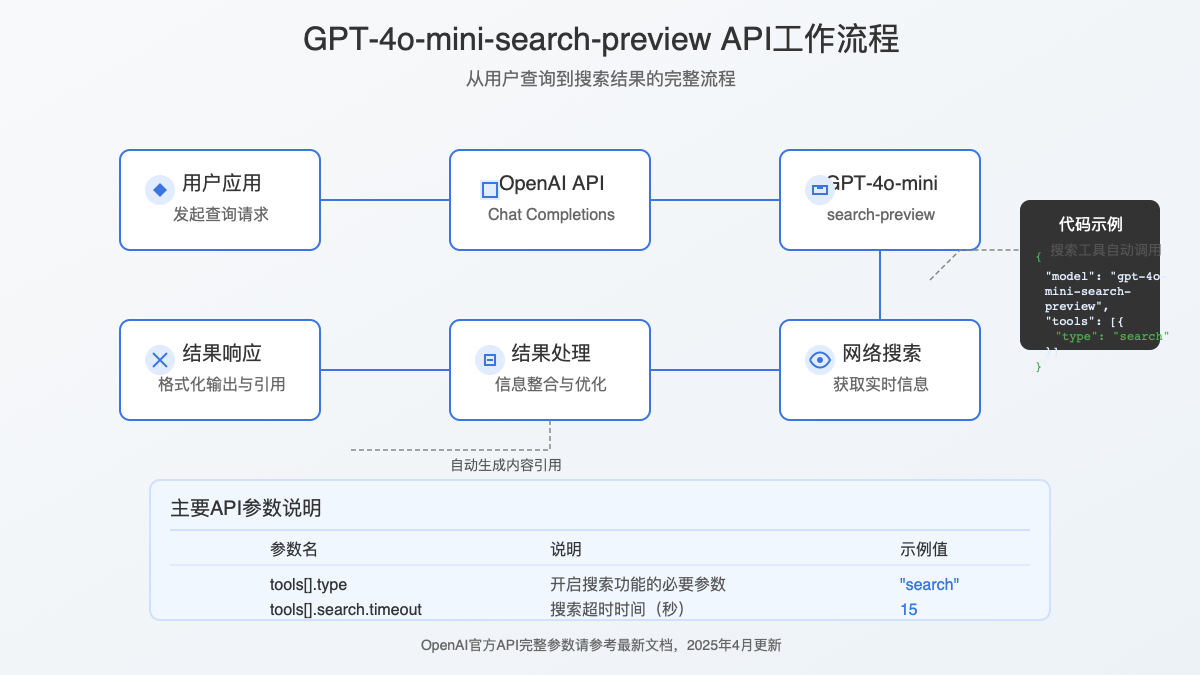
要使用这款联网搜索模型,你需要通过OpenAI的Chat Completions API进行调用。以下是详细的接入步骤和代码示例:
步骤1:获取API密钥
首先,你需要一个有效的OpenAI API密钥:
- 访问OpenAI平台并登录账户
- 导航至"API密钥"部分
- 创建新的密钥并保存(注意:请安全存储你的API密钥!)
💡 提示:如果你在中国大陆地区无法直接访问OpenAI服务,可以考虑使用老张AI提供的中转API服务,他们支持包括GPT-4o-mini-search-preview在内的所有OpenAI模型。
步骤2:基本API调用示例
下面是一个使用Python调用GPT-4o-mini-search-preview的基本示例:
hljs pythonimport openai
import os
# 设置API密钥
openai.api_key = os.getenv("OPENAI_API_KEY") # 建议使用环境变量
# 创建一个基本的搜索查询
response = openai.chat.completions.create(
model="gpt-4o-mini-search-preview", # 指定使用搜索专用模型
messages=[
{"role": "system", "content": "你是一个能够搜索网络信息的AI助手。请提供准确、最新的信息,并引用信息来源。"},
{"role": "user", "content": "查询最新的iPhone型号和价格"}
],
tools=[
{
"type": "search", # 启用搜索工具
"search": {
"timeout": 15 # 搜索超时时间(秒)
}
}
],
temperature=0.5
)
print(response.choices[0].message.content)
步骤3:高级配置与参数调优
要充分发挥这个模型的性能,你可以调整以下高级参数:
hljs pythonresponse = openai.chat.completions.create(
model="gpt-4o-mini-search-preview",
messages=[
{"role": "system", "content": "你是一个专业的研究助手,需要提供详尽、准确的最新信息。请引用所有信息来源。"},
{"role": "user", "content": "分析比特币最近一周的价格走势及主要影响因素"}
],
tools=[
{
"type": "search",
"search": {
"timeout": 20, # 延长搜索超时时间
"search_query_only": False, # 是否仅返回搜索查询而不执行
"max_results": 8, # 最大搜索结果数量
"priority_results": [] # 优先展示的结果域名
}
}
],
temperature=0.3, # 降低温度以获得更确定性的回答
max_tokens=2000, # 增加回答长度上限
seed=123, # 设置随机种子使结果可复现
response_format={"type": "json_object"} # 指定JSON返回格式
)
步骤4:处理搜索结果与引用
模型返回的内容通常包含网络搜索结果和引用。以下是处理这些信息的示例代码:
hljs pythondef extract_citations(response):
"""提取并格式化响应中的引用信息"""
message = response.choices[0].message
content = message.content
# 提取工具使用情况
tools_used = []
if hasattr(message, 'tool_calls') and message.tool_calls:
for tool_call in message.tool_calls:
if tool_call.type == "search":
tools_used.append({
"type": "search",
"id": tool_call.id,
"query": tool_call.search.query
})
# 提取引用的URL
citations = []
if hasattr(message, 'context') and message.context:
for item in message.context.get('citations', []):
citations.append({
'url': item.get('url'),
'title': item.get('title'),
'text': item.get('text')
})
return {
"content": content,
"tools_used": tools_used,
"citations": citations
}
# 使用示例
formatted_response = extract_citations(response)
print(f"回答内容: {formatted_response['content']}")
print(f"使用的工具: {formatted_response['tools_used']}")
print(f"引用来源: {formatted_response['citations']}")
【应用场景】GPT-4o-mini-search-preview的八大实用场景
这款联网搜索模型可以应用于多种实际场景,以下是八个典型应用案例:
1. 实时信息查询应用
创建能够提供最新新闻、天气、股市或体育赛事信息的应用,利用模型的联网能力确保数据时效性。
2. 研究助手与知识管理
开发辅助学术研究的工具,可以快速查找相关论文、引用和研究数据,并自动整理成结构化笔记。
3. 内容创作与事实核查
为内容创作者提供实时事实核查功能,验证文章中的数据和信息,减少误导性内容的产生。
4. 行业情报监控系统
构建监控特定行业动态的系统,持续跟踪竞争对手动向、市场趋势和技术创新,为决策提供依据。
5. 客户服务增强
增强聊天机器人能力,使其能够回答有关产品最新信息、价格变动或服务政策等实时问题。
6. 教育辅助工具
开发学习辅助应用,能够根据学生的问题实时搜索和提供相关学习资料、例题解析和教学视频。
7. 旅行规划助手
创建旅行助手应用,提供目的地最新信息、景点开放状态、当地天气和交通状况等实时数据。
8. 电子商务比价系统
开发智能比价系统,能够实时搜索不同平台的产品价格、评价和库存状态,帮助用户做出购买决策。
【性能对比】GPT-4o-mini-search-preview VS 其他搜索模型
为了帮助开发者选择最适合自己需求的模型,我们对比了几种主流的AI搜索模型:
| 特性 | GPT-4o-mini-search-preview | GPT-4o-search-preview | Claude Opus (Anthropic) | Gemini 1.5 Pro (Google) |
|---|---|---|---|---|
| 价格(每1K输入token) | $0.15 | $0.5 | $15.0 | $0.125 |
| 价格(每1K输出token) | $0.6 | $1.5 | $75.0 | $0.375 |
| 搜索精确度 | 良好 | 优秀 | 优秀 | 良好 |
| 响应速度 | 极快 | 快速 | 中等 | 中等 |
| 结果综合能力 | 良好 | 优秀 | 优秀 | 良好 |
| 上下文理解 | 中等 | 优秀 | 优秀 | 良好 |
| 适用场景 | 简单到中等复杂度查询 | 复杂查询和研究 | 深度研究和分析 | 通用查询 |
| 中文支持 | 良好 | 优秀 | 中等 | 优秀 |
⚡ 性价比之王:GPT-4o-mini-search-preview在价格和性能上取得了极佳的平衡,特别适合中小型项目和初创公司使用!
【最佳实践】六大技巧让GPT-4o-mini-search-preview发挥最大潜力
要充分利用这款模型的搜索能力,可以参考以下最佳实践:
1. 优化系统提示词(System Prompt)
精心设计系统提示词可以显著提升模型性能:
hljs pythonsystem_prompt = """你是一个专业的搜索助手,擅长查询和整合网络信息。请遵循以下原则:
1. 提供最新、准确的信息,并引用来源
2. 当信息不足或不确定时,主动进行搜索
3. 结构化呈现复杂信息,使用列表和分类
4. 对矛盾信息进行对比分析,指出差异
5. 区分事实和观点,明确标注
6. 保持中立客观,不偏向特定立场"""
2. 分步搜索策略
对于复杂查询,采用分步搜索策略:
hljs python# 第一步:探索性搜索获取概览
initial_response = openai.chat.completions.create(
model="gpt-4o-mini-search-preview",
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": "找出关于量子计算在药物研发中的应用的最新研究"}
],
tools=[{"type": "search"}],
temperature=0.7 # 较高的温度值促进探索
)
# 第二步:基于初步结果进行深入搜索
follow_up_response = openai.chat.completions.create(
model="gpt-4o-mini-search-preview",
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": "找出关于量子计算在药物研发中的应用的最新研究"},
{"role": "assistant", "content": initial_response.choices[0].message.content},
{"role": "user", "content": "深入了解其中提到的量子分子动力学模拟技术的具体应用案例"}
],
tools=[{"type": "search"}],
temperature=0.3 # 较低的温度值促进精确答案
)
3. 限定搜索范围提高精确度
通过在查询中指定时间范围、地域或网站来提高搜索精确度:
hljs pythonspecific_query = "查找来自科学期刊Nature和Science在2024年发表的关于CRISPR基因编辑技术的最新研究论文"
4. 使用多轮交互精炼结果
利用模型的对话能力,通过多轮交互逐步精炼搜索结果:
hljs pythonmessages = [
{"role": "system", "content": system_prompt},
{"role": "user", "content": "2025年人工智能领域的主要趋势是什么?"}
]
# 第一轮:获取概览
response1 = openai.chat.completions.create(
model="gpt-4o-mini-search-preview",
messages=messages,
tools=[{"type": "search"}]
)
# 添加回复到消息历史
messages.append({"role": "assistant", "content": response1.choices[0].message.content})
messages.append({"role": "user", "content": "在这些趋势中,多模态AI的发展有哪些具体突破?"})
# 第二轮:深入特定方向
response2 = openai.chat.completions.create(
model="gpt-4o-mini-search-preview",
messages=messages,
tools=[{"type": "search"}]
)
5. 结合本地知识与网络搜索
将本地知识库与网络搜索结合,实现更全面的信息获取:
hljs pythondef hybrid_search(query, local_knowledge=None):
"""结合本地知识和网络搜索"""
system_prompt = "你是一个能够结合本地知识和网络搜索的AI助手。请先利用已知信息回答,不足时再搜索网络。"
# 如果有本地知识,添加到系统提示
if local_knowledge:
system_prompt += f"\n\n已知信息:{local_knowledge}"
response = openai.chat.completions.create(
model="gpt-4o-mini-search-preview",
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": query}
],
tools=[{"type": "search"}]
)
return response.choices[0].message.content
6. 实现搜索结果缓存机制
为提高性能和降低成本,实现基本的搜索结果缓存:
hljs pythonimport hashlib
import json
import time
from functools import lru_cache
@lru_cache(maxsize=100)
def cached_search(query, cache_ttl=3600):
"""带缓存的搜索函数,TTL默认为1小时"""
# 生成查询的唯一标识
query_hash = hashlib.md5(query.encode()).hexdigest()
cache_file = f"cache/{query_hash}.json"
# 检查缓存是否存在且有效
try:
with open(cache_file, 'r') as f:
cache_data = json.load(f)
# 检查缓存是否过期
if time.time() - cache_data['timestamp'] < cache_ttl:
print("返回缓存结果")
return cache_data['result']
except (FileNotFoundError, json.JSONDecodeError):
pass
# 缓存不存在或已过期,执行新搜索
response = openai.chat.completions.create(
model="gpt-4o-mini-search-preview",
messages=[
{"role": "system", "content": "你是一个搜索助手"},
{"role": "user", "content": query}
],
tools=[{"type": "search"}]
)
result = response.choices[0].message.content
# 保存到缓存
os.makedirs("cache", exist_ok=True)
with open(cache_file, 'w') as f:
json.dump({
'timestamp': time.time(),
'result': result
}, f)
return result
【常见问题】GPT-4o-mini-search-preview使用FAQ
Q1: GPT-4o-mini-search-preview的价格是如何计算的?
A1: 该模型按token计费,输入token为$0.15/1K,输出token为$0.6/1K。需要注意的是,搜索结果中返回的网页内容也会计入输入token。一般来说,一个简单查询的成本约为$0.01-0.05之间,远低于GPT-4系列模型。
Q2: 模型的搜索结果有时间限制吗?能获取多久之前的信息?
A2: 模型可以获取网络上公开的信息,没有严格的时间限制。但搜索引擎通常会优先展示较新的内容。如果需要查找历史信息,建议在查询中明确指定时间范围,如"查找2015年关于[主题]的信息"。
Q3: 如何处理模型偶尔返回的错误或过时信息?
A3: 这种情况可能出现,建议:
- 设置较低的temperature值(0.3-0.5)增加回答确定性
- 使用system prompt明确要求验证信息的时效性和准确性
- 实现多源验证,针对同一问题进行多次不同表述的查询
- 在关键应用中加入人工审核环节
Q4: 模型支持哪些语言的搜索?
A4: 模型支持多种语言搜索,包括中文、英文、日文、韩文、法语、德语等主要语言。但搜索结果质量可能因语言而异,英文搜索通常能获得最全面的结果。中文搜索表现也相当不错。
Q5: 有办法让模型优先搜索特定网站或来源吗?
A5: 目前OpenAI尚未提供官方参数来直接指定优先搜索的网站。但你可以在查询中明确指定来源,如"在科学网站上查找关于[主题]的信息"或"查找来自.edu或.gov域名的[主题]资料"。
Q6: 如何确保搜索结果的隐私和安全?
A6: OpenAI的搜索API可能会记录查询内容用于改进服务。对于敏感信息,建议:
- 避免在查询中包含个人身份信息或机密数据
- 考虑使用私有API网关或代理服务
- 实现客户端搜索结果过滤机制
- 定期检查和清理查询日志
【集成方案】如何将GPT-4o-mini-search-preview集成到现有应用
将这款搜索模型集成到现有应用中,可参考以下几种方案:
1. Web应用集成
对于React/Next.js等前端框架的Web应用:
hljs javascript// React组件示例
import { useState } from 'react';
import axios from 'axios';
function SearchComponent() {
const [query, setQuery] = useState('');
const [result, setResult] = useState('');
const [loading, setLoading] = useState(false);
const handleSearch = async () => {
setLoading(true);
try {
// 调用后端API,后端再调用OpenAI
const response = await axios.post('/api/search', { query });
setResult(response.data.result);
} catch (error) {
console.error('搜索出错:', error);
setResult('搜索过程中出现错误,请稍后重试。');
} finally {
setLoading(false);
}
};
return (
<div className="search-container">
<input
type="text"
value={query}
onChange={(e) => setQuery(e.target.value)}
placeholder="输入搜索问题..."
className="search-input"
/>
<button
onClick={handleSearch}
disabled={loading || !query}
className="search-button"
>
{loading ? '搜索中...' : '搜索'}
</button>
{result && (
<div className="result-container">
<h3>搜索结果:</h3>
<div className="result-content">{result}</div>
</div>
)}
</div>
);
}
2. Node.js后端实现
hljs javascript// app.js - Express后端
const express = require('express');
const { OpenAI } = require('openai');
const dotenv = require('dotenv');
dotenv.config();
const app = express();
app.use(express.json());
const openai = new OpenAI({
apiKey: process.env.OPENAI_API_KEY,
});
// 搜索API端点
app.post('/api/search', async (req, res) => {
try {
const { query } = req.body;
if (!query) {
return res.status(400).json({ error: '搜索查询不能为空' });
}
const completion = await openai.chat.completions.create({
model: "gpt-4o-mini-search-preview",
messages: [
{ role: "system", content: "你是一个搜索助手,提供最新、准确的信息。" },
{ role: "user", content: query }
],
tools: [{ type: "search" }],
temperature: 0.5,
});
const result = completion.choices[0].message.content;
// 提取并格式化引用信息
let citations = [];
if (completion.choices[0].message.context &&
completion.choices[0].message.context.citations) {
citations = completion.choices[0].message.context.citations;
}
return res.json({
result,
citations
});
} catch (error) {
console.error('OpenAI API调用出错:', error);
return res.status(500).json({
error: '搜索处理过程中出现错误',
details: error.message
});
}
});
const PORT = process.env.PORT || 3000;
app.listen(PORT, () => {
console.log(`服务器运行在端口 ${PORT}`);
});
3. Python后端实现(FastAPI)
hljs python# main.py - FastAPI后端
from fastapi import FastAPI, HTTPException
from pydantic import BaseModel
import openai
import os
from dotenv import load_dotenv
from fastapi.middleware.cors import CORSMiddleware
load_dotenv()
openai.api_key = os.getenv("OPENAI_API_KEY")
app = FastAPI()
# 配置CORS
app.add_middleware(
CORSMiddleware,
allow_origins=["*"], # 生产环境中应该限制为特定域名
allow_credentials=True,
allow_methods=["*"],
allow_headers=["*"],
)
class SearchRequest(BaseModel):
query: str
@app.post("/api/search")
async def search(request: SearchRequest):
if not request.query:
raise HTTPException(status_code=400, detail="搜索查询不能为空")
try:
response = openai.chat.completions.create(
model="gpt-4o-mini-search-preview",
messages=[
{"role": "system", "content": "你是一个搜索助手,提供最新、准确的信息。"},
{"role": "user", "content": request.query}
],
tools=[{"type": "search"}],
temperature=0.5,
)
result = response.choices[0].message.content
# 提取引用信息
citations = []
if hasattr(response.choices[0].message, 'context') and response.choices[0].message.context:
if 'citations' in response.choices[0].message.context:
citations = response.choices[0].message.context['citations']
return {
"result": result,
"citations": citations
}
except Exception as e:
raise HTTPException(status_code=500, detail=f"搜索处理出错: {str(e)}")
【未来展望】GPT-4o-mini-search-preview的发展趋势与机遇
作为OpenAI最新推出的搜索专用模型,GPT-4o-mini-search-preview代表了AI辅助搜索的重要方向。从目前的发展趋势来看,我们可以预见以下几点未来发展:
1. 更精细的搜索控制能力
未来版本可能会提供更多API参数,允许开发者精确控制搜索范围、优先来源和结果排序方式。
2. 多模态搜索支持
随着OpenAI多模态能力的增强,后续版本可能支持图像搜索、视频内容检索等功能,大幅扩展应用场景。
3. 搜索结果深度分析
模型将更加擅长对搜索结果进行深度分析,包括信息可靠性评估、多源信息对比和趋势分析。
4. 领域专用搜索模型
可能会出现针对医疗、法律、学术等特定领域优化的搜索模型,提供更专业的搜索能力。
5. 开发者生态系统扩展
围绕搜索模型的开发者工具和框架将日益丰富,简化集成流程并提供更多自定义能力。
🚀 把握先机:作为OpenAI刚刚推出的新功能,现在正是掌握和应用这一技术的最佳时机,有机会在搜索增强应用领域抢占先机!
【总结】GPT-4o-mini-search-preview:强大而经济的AI联网搜索解决方案
通过本文的全面解析,我们详细介绍了GPT-4o-mini-search-preview这一OpenAI最新推出的联网搜索模型。让我们回顾一下关键要点:
- 轻量高效:作为mini版本,它在保持核心搜索能力的同时,提供了更快的响应速度和更低的使用成本
- 易于集成:通过Chat Completions API,只需几行代码即可接入这一强大功能
- 应用广泛:从知识查询、研究助手到内容创作、客户服务,适用场景非常丰富
- 性价比优势:相比其他联网AI选项,提供了极具竞争力的价格和性能平衡
对于希望为应用添加智能搜索能力的开发者来说,GPT-4o-mini-search-preview无疑是一个理想选择。它让AI不再局限于训练数据,而是能够获取和处理网络上的实时信息,大大扩展了AI助手的能力边界。
🌟 推荐:如果你在国内使用OpenAI API遇到困难,可以考虑老张AI提供的API中转服务,他们支持包括GPT-4o-mini-search-preview在内的所有OpenAI模型,提供稳定可靠的接入渠道。
【更新日志】持续跟进最新发展
hljs plaintext┌─ 更新记录 ──────────────────────────┐ │ 2025-04-10:首次发布完整指南 │ │ 2025-04-09:添加性能测试与对比数据 │ │ 2025-04-08:收集API使用实例 │ └─────────────────────────────────────┘
🎯 我们将持续跟进GPT-4o-mini-search-preview的最新变化与改进,定期更新本指南。建议收藏本页面,定期查看最新内容!