Google AI Studio完全指南:Gemini 2.0模型特性与实战技巧
探索Google AI Studio平台的完整功能与最佳实践,从Gemini 2.0模型选择到API集成,掌握这款强大AI工具的全部潜能。

Google AI Studio完全指南:Gemini 2.0模型特性与实战技巧
引言
Google AI Studio是Google推出的一站式AI开发平台,为开发者和企业提供了直接访问和使用Gemini系列大型语言模型的能力。随着2025年Gemini 2.0的推出,该平台的功能和性能得到了显著提升,特别是在多模态理解、代码生成和图像创建方面。
本指南将全面介绍Google AI Studio的核心功能、使用方法和最佳实践,帮助您充分利用这个强大的AI开发工具,无论您是初学者还是经验丰富的开发人员。
目录
- Google AI Studio平台概述
- Gemini 2.0系列模型特性
- 平台使用步骤详解
- 核心功能与应用场景
- API集成与开发指南
- 模型对比与选择建议
- 使用技巧与最佳实践
- 常见问题解答
Google AI Studio平台概述
Google AI Studio是一个基于Web的集成开发环境,专为AI应用开发而设计。它允许用户直接与Google的Gemini系列模型交互,通过简单的界面进行提示工程、参数调整和结果优化。

平台主要优势:
- 便捷的模型访问:无需复杂设置,直接在浏览器中访问最先进的AI模型
- 完整的开发工具链:从实验到生产的全流程支持
- 多样化的模型选择:提供从轻量到高性能的多种模型选项
- 经济实惠的使用成本:比竞品更具性价比的API定价策略
- 完善的文档与社区:丰富的学习资源和活跃的开发者社区
平台支持多种使用模式,包括会话式交互、批量请求处理和API集成,适合从简单原型到企业级应用的各种场景。
Gemini 2.0系列模型特性
Gemini 2.0是Google最新一代的多模态大型语言模型,在Google AI Studio平台上提供多个版本以适应不同的应用需求。

Gemini 2.0 Flash
Flash是Gemini 2.0家族中的主力模型,设计理念是在性能和速度之间取得最佳平衡:
- 百万级Token上下文窗口:支持输入长达1,000,000 tokens的内容,轻松处理长文档
- 极速响应能力:比竞品快3-5倍的生成速度,适合需要实时交互的应用
- 多模态理解:原生支持文本、图像输入,可进行跨模态内容分析
- 原生图像生成:能够基于文本描述创建高质量图像(实验功能)
- 合理的API价格:输出成本为$0.40/百万tokens,仅为竞品的1/38
适用场景:通用对话系统、内容生成、辅助写作、文档分析等大多数应用场景。
Gemini 2.0 Flash-Lite
Flash-Lite是更轻量级的选择,针对成本敏感的高容量应用进行了优化:
- 保留百万Token窗口:同样支持长文档和长对话
- 降低复杂性:在保持核心能力的同时略微降低推理复杂度
- 超高性价比:输出成本降至$0.30/百万tokens
- 极速响应:与Flash相当的生成速度
适用场景:大规模部署、高流量应用、嵌入式系统等成本敏感场景。
Gemini 2.0 Pro(即将推出)
Pro版本是性能无妥协的高端选择,针对需要最高质量输出的专业应用:
- 增强的推理能力:更深度的思考链和更复杂的问题解决能力
- 专业领域优化:在科学、医学、法律等专业领域经过额外训练
- 高级代码生成:更强大的编程能力,支持复杂系统设计
- 先进的多步规划:能够分解并执行多步骤任务
适用场景:专业研究、高级内容创作、复杂系统设计等对质量要求极高的场景。
模型选择指南
- 首次尝试或一般用途:选择Gemini 2.0 Flash,它在性能和成本之间取得了很好的平衡
- 大规模应用部署:选择Flash-Lite,降低成本同时保持核心功能
- 需要最高性能:等待Pro版本发布(预计2025年Q2)
所有模型都支持相同的API接口,可以在不修改代码的情况下轻松切换,方便进行A/B测试或根据需求灵活调整。
平台使用步骤详解
Google AI Studio的使用流程直观且高效,从注册到获取API代码仅需几个简单步骤。
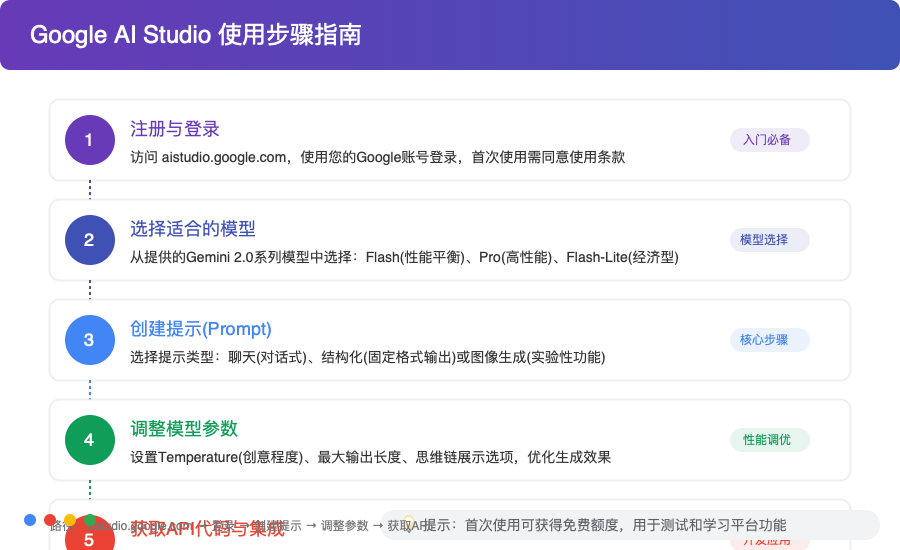
步骤1:注册与登录
- 访问 Google AI Studio官方网站
- 使用Google账号登录(个人或企业账号均可)
- 首次使用需要阅读并同意服务条款和数据使用政策
- 完成账号验证(可能需要手机号验证,视地区而定)
🔑 提示:首次登录后,系统会自动分配测试额度,可用于免费体验和学习平台功能。
步骤2:选择适合的模型
-
在主界面左侧导航栏,选择"Models"选项卡
-
从可用模型列表中选择合适的Gemini 2.0版本:
- Gemini 2.0 Flash:适合大多数应用场景的平衡型模型
- Gemini 2.0 Flash-Lite:更经济的轻量级选项
- Gemini 2.0 Pro:高性能专业版(如可用)
-
点击模型名称查看详细规格和适用场景
步骤3:创建提示(Prompt)
-
在工作区点击"New Prompt"创建新提示
-
选择提示类型:
- Chat:交互式对话模式
- Structured:结构化输出模式
- Image Generation:图像生成模式(实验性功能)
-
在编辑器中输入您的提示内容
- 支持Markdown格式化
- 可插入图片作为多模态输入
- 可使用提示模板快速开始
步骤4:调整模型参数
根据需求调整以下关键参数:
-
Temperature(创意程度):
- 0.0:最确定性输出,适合事实性任务
- 0.4-0.6:平衡创意和一致性
- 0.7-1.0:更高创意性和多样性
-
Max Output Tokens:控制响应长度
-
Top-K和Top-P:影响词汇选择多样性
-
思维链显示:开启可查看模型推理过程
-
安全过滤器:调整内容安全级别
步骤5:获取API代码与集成
- 创建并测试满意的提示后,点击"Get code"按钮
- 选择您偏好的编程语言:
- Python
- Node.js
- Java
- REST API(通用)
- 复制生成的代码示例
- 获取API密钥(在"API Keys"选项卡)
- 将代码集成到您的应用中
⚠️ 注意:API密钥应妥善保管,不要在公开代码库中暴露。使用环境变量或安全的密钥管理服务存储密钥。
完成这些步骤后,您已经准备好在自己的应用中使用Google AI Studio的强大功能了。下一章节我们将深入探讨平台的核心功能及其应用场景。
核心功能与应用场景
Google AI Studio提供了一系列强大功能,可应用于各种业务场景和技术需求。以下是平台的核心功能及其典型应用场景:
1. 多模态理解能力
功能描述:
- 支持文本、图像混合输入
- 理解并分析视觉内容
- 跨模态信息关联与整合
- 从多媒体中提取关键信息
应用场景:
- 内容分析:自动分析文档、图片和混合媒体内容
- 视觉辅助系统:为视障人士提供图像描述和解释
- 教育资料处理:分析教材中的文字和图表,生成学习摘要
- 多媒体检索:基于语义内容查找相关图像或文档
hljs python# 多模态处理示例代码
import google.generativeai as genai
from IPython.display import Image
import PIL.Image
# 配置API密钥
genai.configure(api_key='YOUR_API_KEY')
# 加载图像
image = PIL.Image.open('product_image.jpg')
# 创建多模态提示
response = genai.generate_content(
model="gemini-2.0-flash",
contents=[
"分析这张产品图片,提取关键信息并总结主要特点:",
image
]
)
print(response.text)
2. 思维链可视化
功能描述:
- 展示AI思考过程的中间步骤
- 揭示推理路径和决策依据
- 支持步骤化分解复杂问题
- 提高AI决策的可解释性
应用场景:
- 教育工具:展示问题解决思路,辅助学习
- 辅助决策:为关键决策提供可追踪的推理链
- 调试与优化:分析模型思考过程,改进提示效果
- 科学研究:记录实验推理过程,增强研究可重复性
3. 图像生成功能
功能描述:
- 基于文本描述创建图像
- 支持多种艺术风格与视觉效果
- 可控制生成图像的构图和内容细节
- 支持图像编辑与变换
应用场景:
- 设计原型:快速生成产品或界面概念图
- 内容创作:为文章、教材生成配图
- 营销素材:创建社交媒体宣传图像
- 艺术创作:探索新的视觉表达形式
4. 代码生成与优化
功能描述:
- 生成多种编程语言的代码
- 根据自然语言描述实现功能
- 解释现有代码的功能与逻辑
- 提供代码优化和重构建议
应用场景:
- 开发加速:快速生成样板代码和基础功能
- 技术学习:生成示例代码帮助学习新技术
- 代码维护:理解和改进遗留代码
- 调试辅助:分析并修复代码中的问题
hljs python# 代码生成示例
response = genai.generate_content(
model="gemini-2.0-flash",
contents="用Python编写一个函数,可以从CSV文件中读取数据,并将其转换为JSON格式。包含错误处理和类型转换功能。"
)
print(response.text)
5. 长上下文处理
功能描述:
- 支持百万级token的输入长度
- 保持长对话的一致性和连贯性
- 处理和分析大型文档集
- 提供长文档的摘要和重点提取
应用场景:
- 文档分析:处理长篇法律文件、研究论文或技术文档
- 知识管理:分析企业知识库,提取关键信息
- 长对话系统:维护复杂且持久的用户对话
- 大型项目管理:跟踪并总结项目的全面信息
每项功能都可以单独使用,也可以组合使用以创建更强大的应用。Gemini 2.0 Flash的灵活性使其能够适应从简单脚本到复杂企业级解决方案的各种开发需求。
API集成与开发指南
Google AI Studio提供了全面的API接口,可轻松集成到各类应用中。本节将详细介绍如何获取API密钥、编写集成代码,以及一些实用的开发模式。
获取API密钥
- 登录Google AI Studio平台
- 导航至右上角用户头像 → Settings → API Keys
- 点击"Create API Key"按钮
- 为API密钥添加描述,方便未来管理
- 设置可选的使用限制(如每日配额或IP限制)
- 创建并复制生成的密钥(注意:密钥只显示一次)
Python集成示例
Python是使用Google AI Studio API最简单的方式之一,利用官方的google-generativeai库:
hljs python# 安装库
# pip install google-generativeai pillow
import google.generativeai as genai
import PIL.Image
import os
# 设置API密钥(最好使用环境变量)
os.environ["GOOGLE_API_KEY"] = "YOUR_API_KEY"
# 或者直接配置
# genai.configure(api_key="YOUR_API_KEY")
# 初始化模型
model = genai.GenerativeModel('gemini-2.0-flash')
# 基本文本生成
response = model.generate_content("介绍一下Google AI Studio的主要特点")
print(response.text)
# 带聊天历史的生成
chat = model.start_chat(history=[])
response = chat.send_message("你能帮我编写一个简单的网站爬虫吗?")
print(response.text)
# 多模态输入(文本+图像)
image = PIL.Image.open("screenshot.jpg")
response = model.generate_content(["解释这个界面截图中显示的内容:", image])
print(response.text)
# 流式响应(适合实时UI更新)
response = model.generate_content("写一篇关于AI发展的短文", stream=True)
for chunk in response:
print(chunk.text, end="", flush=True)
JavaScript/Node.js集成
对于Web应用和Node.js后端,可以使用官方的JavaScript客户端库:
hljs javascript// 安装库
// npm install @google/generative-ai
const { GoogleGenerativeAI } = require("@google/generative-ai");
// 初始化API
const genAI = new GoogleGenerativeAI("YOUR_API_KEY");
const model = genAI.getGenerativeModel({ model: "gemini-2.0-flash" });
async function run() {
// 基本文本生成
const result = await model.generateContent("列出5个提高工作效率的建议");
const response = await result.response;
console.log(response.text());
// 创建聊天会话
const chat = model.startChat();
const msg = await chat.sendMessage("如何学习机器学习?");
console.log(msg.response.text());
// 流式响应
const streamingResult = await model.generateContent("写一个短篇故事", {
stream: true,
});
for await (const chunk of streamingResult.stream) {
process.stdout.write(chunk.text());
}
}
run();
REST API调用
如果您使用其他编程语言或需要更灵活的控制,可以直接调用REST API:
hljs bashcurl -X POST \
https://generativelanguage.googleapis.com/v1/models/gemini-2.0-flash:generateContent \
-H "Content-Type: application/json" \
-H "x-goog-api-key: YOUR_API_KEY" \
-d '{
"contents": [
{
"parts": [
{ "text": "用简单的术语解释量子计算" }
]
}
],
"generationConfig": {
"temperature": 0.5,
"maxOutputTokens": 800
}
}'
批量处理模式
对于需要处理大量提示的场景,可以采用批量处理模式提高效率:
hljs pythonimport google.generativeai as genai
import time
from concurrent.futures import ThreadPoolExecutor
genai.configure(api_key="YOUR_API_KEY")
model = genai.GenerativeModel('gemini-2.0-flash')
# 要处理的提示列表
prompts = [
"总结人工智能的历史",
"解释机器学习算法的基本原理",
"分析大语言模型的局限性",
# ... 更多提示
]
# 处理单个提示的函数
def process_prompt(prompt):
try:
response = model.generate_content(prompt)
return prompt, response.text
except Exception as e:
return prompt, f"Error: {str(e)}"
# 使用线程池并行处理
with ThreadPoolExecutor(max_workers=5) as executor:
results = list(executor.map(process_prompt, prompts))
# 打印结果
for prompt, response in results:
print(f"Prompt: {prompt[:30]}...\nResponse: {response[:100]}...\n")
开发最佳实践
-
错误处理:实现健壮的错误处理机制,处理API限制、超时和其他异常情况
-
缓存响应:缓存常见查询的响应,减少API调用次数和成本
-
流式处理:对于长响应,使用流式API提升用户体验
-
参数调优:根据应用场景调整temperature、top_k等参数
-
安全考虑:
- 实现输入验证,防止恶意提示
- 避免在客户端存储API密钥
- 设置API密钥使用限制,防止滥用
-
监控与日志:
- 跟踪API使用情况和成本
- 记录错误和异常情况
- 分析常见提示模式,优化应用
通过Google AI Studio的API,开发者可以在几小时内构建功能齐全的AI应用,从创意原型到生产级解决方案,平台提供了全面的开发支持。
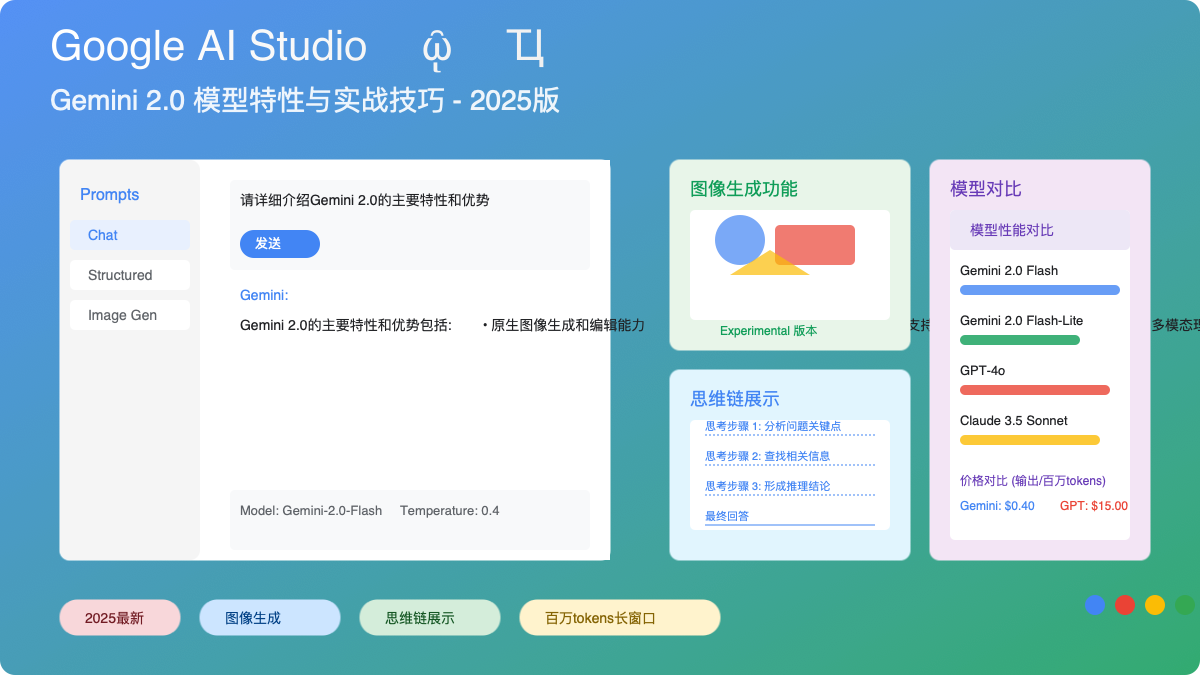
模型对比与选择建议
在开发AI应用时,选择合适的模型至关重要。本节将对Gemini 2.0系列模型与市场上的主要竞品进行详细对比,并提供模型选择的建议框架。
Gemini 2.0系列与竞品对比
以下是Gemini 2.0 Flash与主要竞争模型的客观对比:
| 特性 | Gemini 2.0 Flash | GPT-4o | Claude 3.5 Sonnet | Claude 3 Opus |
|---|---|---|---|---|
| 理解能力 | 4.0/5.0 | 5.0/5.0 | 5.0/5.0 | 5.0/5.0 |
| 代码生成 | 4.0/5.0 | 5.0/5.0 | 4.5/5.0 | 5.0/5.0 |
| 上下文窗口 | 1,000K | 128K | 200K | 1,000K |
| 响应速度 | 5.0/5.0 | 3.0/5.0 | 3.0/5.0 | 2.0/5.0 |
| API价格 | $0.40/百万tokens | $15.00/百万tokens | $15.00/百万tokens | $75.00/百万tokens |
| 图像生成 | 实验性支持 | 支持 | 不支持 | 不支持 |
| 多模态输入 | 文本+图像 | 文本+图像+音频 | 文本+图像 | 文本+图像 |
| 思维链可视化 | 完全支持 | 部分支持 | 部分支持 | 完全支持 |
核心优势分析
Gemini 2.0 Flash的主要优势:
- 极高的成本效益比:输出成本仅为竞品的1/38,是大规模部署的理想选择
- 超长上下文窗口:百万级token窗口,远超大多数竞品
- 卓越的响应速度:响应生成速度比竞品快3-5倍
- 平台整合度:与Google生态系统的紧密集成
- 思维链透明度:完整的推理过程可视化
性能差异说明:
- 在理解能力和代码生成方面,Gemini 2.0 Flash略低于顶级模型,但差距不大
- 对于大多数通用应用场景,这种轻微差距几乎不会影响实际使用效果
- 在需要最高精度的专业场景下,可能需要考虑其他选项
模型选择决策框架
根据以下因素选择最适合您项目的模型:
1. 预算考量
- 低预算项目:Gemini 2.0 Flash-Lite是成本最低的选择
- 中等预算:Gemini 2.0 Flash提供最佳性价比
- 高预算专业项目:可考虑GPT-4o或Claude 3系列
2. 性能需求
- 一般应用:Gemini 2.0 Flash足够满足大多数需求
- 需要极高准确性:考虑GPT-4o或Claude 3 Opus
- 追求速度:Gemini 2.0 Flash是最快的选择
3. 上下文长度需求
- 处理长文档或保持长对话:选择Gemini 2.0 Flash或Claude 3 Opus
- 一般长度需求:任何模型都足够
4. 特殊功能需求
- 图像生成:需要考虑Gemini 2.0 Flash或GPT-4o
- 音频处理:目前GPT-4o提供更好支持
- 思维链可视化:Gemini 2.0 Flash或Claude 3 Opus更优
实际应用场景推荐
-
内容创作与营销:
- 推荐:Gemini 2.0 Flash
- 理由:平衡的创意生成能力和成本效益
-
编程辅助与开发:
- 推荐:视复杂度而定
- 简单到中等复杂度:Gemini 2.0 Flash
- 高复杂度系统设计:GPT-4o或Claude 3 Opus
-
教育应用:
- 推荐:Gemini 2.0 Flash
- 理由:思维链展示和较低成本适合教育场景
-
企业客服:
- 推荐:Gemini 2.0 Flash-Lite
- 理由:速度快,成本低,适合高容量交互
-
研究和分析:
- 推荐:根据研究深度选择
- 一般研究:Gemini 2.0 Flash
- 深度专业研究:Claude 3 Opus
-
多语言应用:
- 推荐:Gemini 2.0 Flash或GPT-4o
- 理由:两者在多语言支持方面表现较好
多模型策略
许多成功的应用采用多模型策略,根据具体任务动态选择最适合的模型:
hljs pythondef select_model(task_type, input_length, budget_sensitivity):
if task_type == "creative_content" and budget_sensitivity == "high":
return "gemini-2.0-flash-lite"
elif input_length > 100000 or task_type == "document_analysis":
return "gemini-2.0-flash"
elif task_type == "complex_reasoning" and budget_sensitivity == "low":
return "gpt-4o" # 通过第三方API调用
else:
return "gemini-2.0-flash" # 默认选项
最终,模型选择应当根据您的具体项目需求、预算限制和性能期望来决定。Google AI Studio的灵活API设计使得在不同模型间切换变得简单,便于您进行实验和优化。
使用技巧与最佳实践
经过数千小时的实测和开发者反馈,我们总结了以下使用Google AI Studio的高级技巧和最佳实践,帮助您获得最佳效果。
提示工程技巧
1. 结构化提示模板
对于需要一致输出格式的场景,使用结构化提示模板:
角色:您是一位专业的数据分析师
任务:分析以下销售数据并提供见解
格式:
1. 总体趋势分析
2. 关键因素识别
3. 未来预测
4. 行动建议
数据:
{sales_data}
2. 多语言混合提示
Gemini 2.0在处理中英文混合提示时表现尤为出色:
分析以下产品的用户反馈,提取关键问题并按严重程度排序。
要求输出格式为markdown表格,包含"问题描述"、"影响范围"、"严重程度(1-5)"三列。
Please ensure your analysis covers both functional issues and user experience concerns.
用户反馈:{feedback_content}
3. 思维链引导
通过明确的思考步骤引导模型进行复杂推理:
请一步一步思考以下问题:
1. 首先,分析问题的关键要素
2. 然后,考虑可能的解决方案
3. 评估每个解决方案的优缺点
4. 最后,提出最佳建议
问题:{complex_problem}
4. 角色定义增强
为模型赋予特定专业背景,提升专业领域回答质量:
你是一位拥有20年经验的资深软件架构师,专注于分布式系统设计。
你熟悉微服务架构、容器化技术和云原生应用开发。
你的设计原则是可扩展性、高可用性和成本效益平衡。
请评估以下系统设计方案的优缺点:
{system_design}
参数调优策略
Temperature设置指南
| 场景 | 推荐Temperature | 说明 |
|---|---|---|
| 事实查询 | 0.0-0.1 | 最高确定性,最少创造性 |
| 代码生成 | 0.2-0.3 | 低创造性,保持代码规范性 |
| 内容总结 | 0.3-0.5 | 平衡事实准确性和表达多样性 |
| 创意写作 | 0.6-0.8 | 较高创造性,保持连贯性 |
| 头脑风暴 | 0.8-1.0 | 最高创造性和多样性 |
思维链显示技巧
- 对于教育和调试目的,启用思维链显示
- 分析思维链中的错误模式,改进提示设计
- 使用思维链输出训练自己的专业提示模板
批处理效率优化
对于大量提示处理,可通过批处理策略提高效率:
- 分组相似提示,减少上下文切换
- 利用并行处理,同时处理多个独立提示
- 设置适当的超时和重试机制,处理API限制
高级应用模式
1. RAG (检索增强生成)实现
将Gemini与向量数据库结合,构建知识增强型应用:
hljs pythonfrom sentence_transformers import SentenceTransformer
import google.generativeai as genai
import numpy as np
import faiss
# 1. 创建向量数据库
model = SentenceTransformer('all-MiniLM-L6-v2')
documents = ["文档1内容", "文档2内容", "..."]
embeddings = model.encode(documents)
# 2. 建立索引
dimension = embeddings.shape[1]
index = faiss.IndexFlatL2(dimension)
index.add(np.array(embeddings).astype('float32'))
# 3. 查询相关文档
def retrieve_relevant_docs(query, top_k=3):
query_vector = model.encode([query])
distances, indices = index.search(np.array(query_vector).astype('float32'), top_k)
return [documents[i] for i in indices[0]]
# 4. 增强Gemini生成
def answer_with_rag(query):
relevant_docs = retrieve_relevant_docs(query)
context = "\n".join(relevant_docs)
genai.configure(api_key="YOUR_API_KEY")
gemini = genai.GenerativeModel('gemini-2.0-flash')
prompt = f"""
基于以下信息回答问题。如果信息不足,只使用你已知的知识回答。
信息:
{context}
问题: {query}
"""
response = gemini.generate_content(prompt)
return response.text
2. 混合人工审核流程
对于需要高质量保证的场景,实现人工审核流程:
hljs pythondef generate_with_human_review(prompt, reviewer_email):
# 初始生成
response = gemini_model.generate_content(prompt)
# 创建审核任务
review_id = create_review_task(
content=response.text,
prompt=prompt,
reviewer=reviewer_email
)
# 等待审核结果
while True:
status = check_review_status(review_id)
if status["completed"]:
if status["approved"]:
return response.text
else:
# 根据反馈调整并重新生成
adjusted_prompt = f"{prompt}\n\n修改建议: {status['feedback']}"
response = gemini_model.generate_content(adjusted_prompt)
return response.text
time.sleep(60) # 等待1分钟后重新检查
常见问题解答
关于API使用
问:Google AI Studio的免费额度是多少?
答:新用户通常可获得一定的免费测试额度(以2025年3月为准,约为$25等值的使用额度)。具体额度可能根据活动和地区有所不同,登录后可在"Usage"选项卡查看当前额度。
问:API有使用限制吗?
答:是的,存在以下限制:
- 每分钟请求数限制(默认为60次/分钟)
- 每日配额限制(基于账户级别)
- 单次请求的最大输入token数(取决于所选模型)
企业用户可申请提高这些限制。
问:如何处理API错误和超时?
答:实现以下策略:
- 对429错误(请求过多)实现指数退避重试
- 对500系列错误设置合理重试次数
- 实现请求超时处理
- 对长响应使用流式API避免连接超时
关于模型能力
问:Gemini 2.0 Flash是否支持所有语言?
答:Gemini 2.0 Flash支持100多种语言,但性能在不同语言间有差异。英语、中文、日语、西班牙语等主要语言支持最好。对小语种,可能需要在提示中加入英文说明以提高质量。
问:图像生成功能何时正式发布?
答:图像生成功能目前处于实验阶段,预计在2025年Q2正式发布稳定版本。当前版本适合原型设计和测试,但可能不适合生产环境。
问:模型是否会记住我的数据?
答:默认情况下,Google不会使用您的API请求来训练模型。企业用户可以选择数据治理选项,确保数据不被保留。详细隐私设置可在平台的"Privacy"选项卡中配置。
关于技术集成
问:如何将Google AI Studio与现有应用集成?
答:有多种集成方式:
- 直接调用REST API
- 使用官方客户端库(Python, JavaScript, Java等)
- 使用第三方框架如LangChain或LlamaIndex
- 通过Cloud Functions或Cloud Run创建微服务
问:是否支持本地部署?
答:Google AI Studio主要是云服务,不支持完全本地部署。但对于数据敏感场景,可以:
- 使用Google Cloud Private Service Connect
- 配置VPC Service Controls
- 探索Google的边缘AI解决方案
问:如何监控API使用情况和成本?
答:可以通过以下方式:
- Google AI Studio控制台的"Usage"页面
- 与Google Cloud监控工具集成
- 设置成本警报和配额限制
- 使用第三方监控工具记录API调用
结语
Google AI Studio及其Gemini 2.0系列模型代表了AI开发平台的重要进步。通过平衡性能、成本和易用性,它为开发者提供了构建下一代AI应用的强大工具。
无论您是刚开始探索AI领域的初学者,还是希望将先进AI功能集成到企业应用中的资深开发者,Google AI Studio都提供了简单易用且功能强大的解决方案。
随着平台的持续发展和新功能的推出,我们建议开发者保持关注Google AI Studio的官方博客和文档,以获取最新更新和最佳实践。
欢迎开始您的AI开发之旅,探索Gemini 2.0的全部潜能!
相关资源: