Gemini 2.5 Pro vs Claude 3.7 Sonnet: Ultimate Comparison Guide 2025
Comprehensive 2025 analysis comparing Gemini 2.5 Pro vs Claude 3.7 Sonnet - featuring performance benchmarks, coding capabilities, pricing, context windows, and access methods. Discover which leading AI model best fits your specific needs.


Gemini 2.5 Pro vs Claude 3.7 Sonnet: Comprehensive Comparison Guide 2025

🔥 May 2025 Update: This analysis compares Google's Gemini 2.5 Pro and Anthropic's Claude 3.7 Sonnet based on the latest benchmarks and real-world testing. Discover which model best fits your specific needs and how to access both cost-effectively.
Introduction: The State of Advanced AI Models in 2025
The AI landscape has evolved dramatically in early 2025, with Google and Anthropic releasing their most capable models to date. Gemini 2.5 Pro (released March 2025) and Claude 3.7 Sonnet (released February 2025) represent the cutting edge of large language model capabilities, each bringing unique strengths to the table.
This comprehensive comparison examines both models across multiple dimensions:
- Technical specifications and capabilities
- Performance benchmarks in key areas
- Real-world application performance
- Pricing and cost considerations
- Access methods and integration options
Technical Specifications: Core Capabilities and Design Philosophy
| Feature | Gemini 2.5 Pro | Claude 3.7 Sonnet |
|---|---|---|
| Release Date | March 2025 | February 2025 |
| Training Cutoff | January 2025 | April 2024 |
| Context Window | 1M tokens (2M coming soon) | 200K tokens |
| Multimodal Support | Text, images, audio, video | Text, images |
| Reasoning Architecture | Multi-stage reasoning | Extended thinking with visible steps |
| API Access | Google AI Studio, Vertex AI | Claude.ai, Anthropic API, AWS Bedrock |
| Max Output Tokens | 64,000 | 128,000 |
Gemini 2.5 Pro: Google's Thinking Model
Gemini 2.5 Pro is designed as a "thinking model" that approaches complex problems through a methodical multi-stage reasoning process. It excels in tasks requiring deep analytical thinking, mathematical reasoning, and processing diverse input formats. The massive 1M token context window (with 2M tokens in development) allows it to analyze extensive documents and datasets in a single prompt.
Claude 3.7 Sonnet: Anthropic's Hybrid Reasoning Approach
Claude 3.7 Sonnet introduces a hybrid reasoning approach, featuring an innovative "Extended Thinking" mode that makes the model's reasoning process visible to users. This transparency helps users understand how the model arrives at conclusions and generates content. While it has a smaller context window than Gemini (200K tokens), Claude often demonstrates superior understanding of nuanced instructions and excels in creative content generation.
Performance Benchmark Analysis
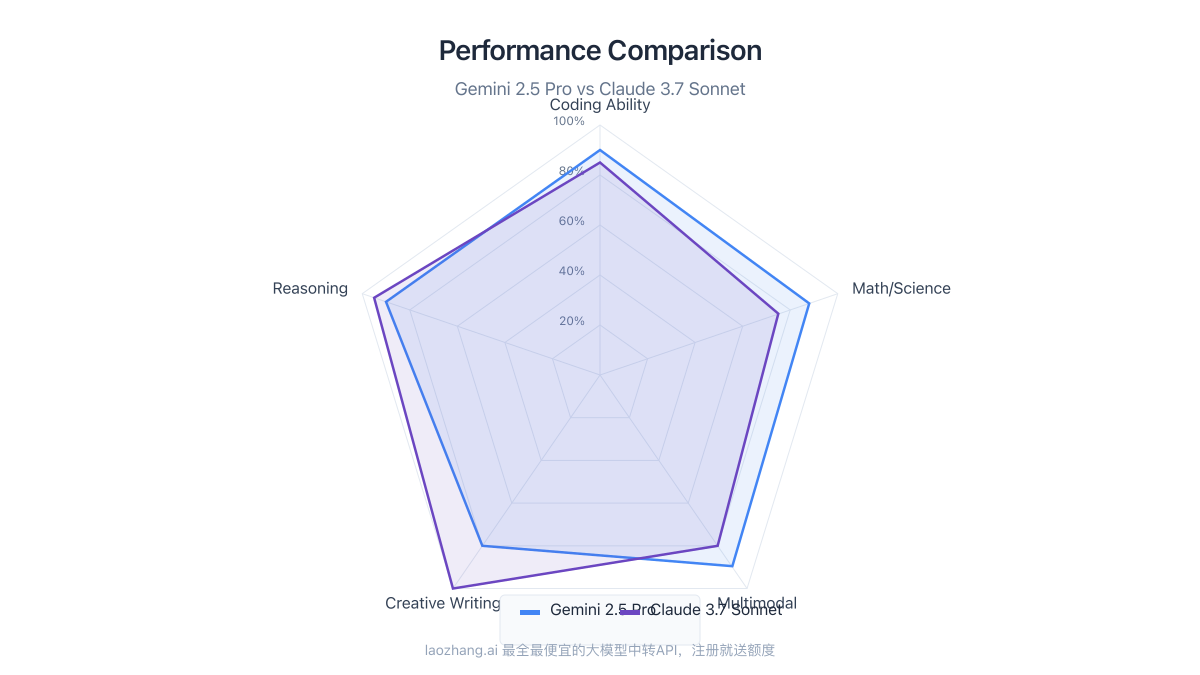
Our assessment of both models across key performance dimensions reveals distinct strengths. Let's examine each area in detail:
Coding Capability
Both models demonstrate exceptional coding abilities, with Gemini 2.5 Pro scoring slightly higher in benchmark tests (84% vs. 82% on SWE-Bench). However, real-world testing reveals interesting nuances:
-
Gemini 2.5 Pro: Excels in algorithm optimization, complex debugging, and backend development. It generates more efficient code for computationally intensive tasks and integrates particularly well with Google's ecosystem tools.
-
Claude 3.7 Sonnet: Produces more readable, well-documented code with comprehensive error handling. Its code is often more maintainable, and it shows particular strength in frontend development and user interface design.
For most developers, either model will provide high-quality coding assistance, but specialized tasks may benefit from choosing the model with the corresponding strength.
Mathematical and Scientific Reasoning
Gemini 2.5 Pro demonstrates a significant advantage in mathematical and scientific reasoning:
- AIME (American Invitational Mathematics Examination): Gemini scores 92% vs. Claude's 75%
- GPQA (Graduate-level Physics Questions Assessment): Gemini scores 93% vs. Claude's 79%
These results suggest that for complex mathematical modeling, scientific research, or engineering applications, Gemini 2.5 Pro offers superior performance. The gap is particularly noticeable in multi-step mathematical proofs and physics problem-solving.
Creative Writing and Content Generation
Claude 3.7 Sonnet maintains its reputation for superior content creation:
- Creative writing samples from Claude demonstrate greater narrative coherence, stylistic consistency, and emotional resonance
- Marketing copy tests show Claude generating more persuasive and audience-appropriate content
- Claude's outputs typically require less editing for tone and style consistency
For content creators, marketers, and anyone needing high-quality written materials, Claude 3.7 Sonnet provides a slight but meaningful advantage.
Multimodal Capabilities
Gemini 2.5 Pro offers significantly broader multimodal capabilities:
- Processes text, images, audio, and video inputs
- Demonstrates better understanding of visual content and spatial relationships
- Shows superior performance in tasks requiring integration of information across modalities
Claude 3.7 Sonnet handles text and image inputs well but lacks audio and video processing capabilities. For applications requiring rich multimedia understanding, Gemini is the clear choice.
Reasoning and Problem-Solving
Both models excel at complex reasoning tasks but with different approaches:
-
Gemini 2.5 Pro: Utilizes multi-stage reasoning to break down problems systematically. It excels in structured problem-solving and can more effectively handle problems with clear logical steps.
-
Claude 3.7 Sonnet: The Extended Thinking mode provides transparent reasoning, showing how it approaches problems. It often performs better on tasks requiring nuanced understanding of implicit information or ethical considerations.
In MMLU (Massive Multitask Language Understanding) benchmarks, Gemini scores 85% vs. Claude's 82%, but Claude shows stronger performance in ethics and philosophy subdomains.
Pricing and Cost Considerations
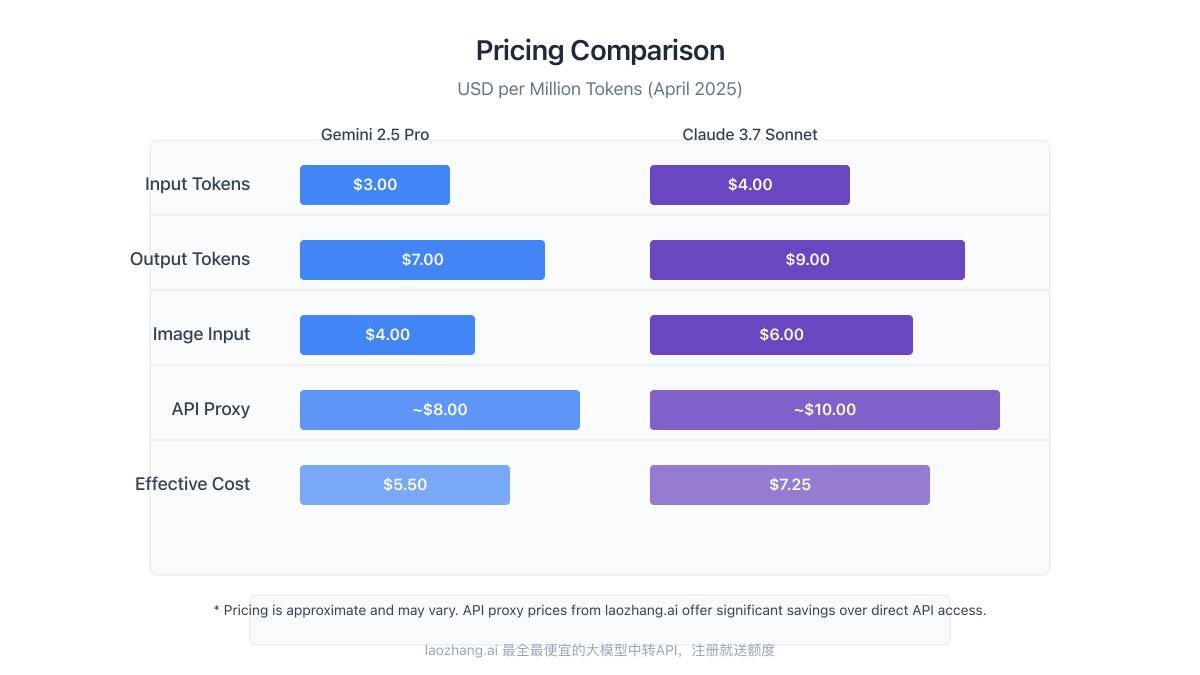
Pricing is a critical factor for many users, particularly for applications requiring high volumes of API calls. Our analysis shows Gemini 2.5 Pro generally offers more favorable pricing:
| Category | Gemini 2.5 Pro | Claude 3.7 Sonnet |
|---|---|---|
| Input Tokens | $3.00 per million | $4.00 per million |
| Output Tokens | $7.00 per million | $9.00 per million |
| Image Processing | $4.00 per million tokens | $6.00 per million tokens |
For high-volume applications, this price difference can be significant. However, proxy services like laozhang.ai offer substantial discounts on both models (typically 20-50% below official rates), which can change the cost calculation significantly.
Cost Optimization Strategies
To maximize value from either model:
- Optimize Prompts: Craft efficient prompts that minimize token usage while maintaining clarity
- Use Caching: Implement caching for common queries to reduce redundant API calls
- Consider Proxy Services: Services like laozhang.ai offer discounted access to both models
- Batch Processing: Consolidate requests where possible to reduce overhead
- Monitor Usage: Implement robust usage tracking to identify optimization opportunities
Real-World Applications: Choosing the Right Model
Based on our analysis, here are recommendations for specific use cases:
Best Uses for Gemini 2.5 Pro
- Data Science and Analysis: Superior mathematical reasoning and larger context window
- Research Applications: Better scientific reasoning and ability to process extensive papers
- Multimedia Applications: More comprehensive multimodal capabilities
- High-Volume API Usage: More favorable pricing structure
- Complex Backend Development: Stronger algorithmic optimization
Best Uses for Claude 3.7 Sonnet
- Content Creation: Superior creative writing and stylistic consistency
- Customer-Facing Applications: Better tone management and ethical guardrails
- Technical Documentation: Clearer explanations and more readable outputs
- Frontend Development: Better UI/UX design capabilities
- Tasks Requiring Nuanced Understanding: More adept at interpreting complex instructions
Access Options: Direct API vs. Proxy Services
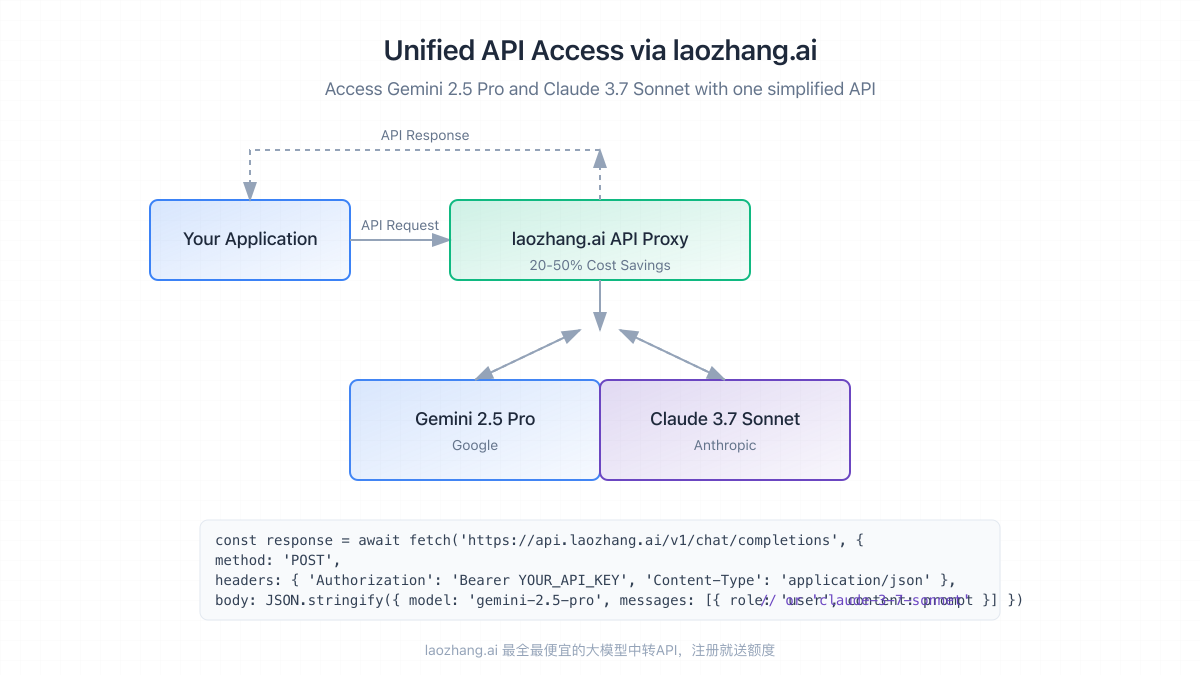
Official API Access
Both models are available through their respective official channels:
- Gemini 2.5 Pro: Access via Google AI Studio or Google Cloud's Vertex AI
- Claude 3.7 Sonnet: Available through Anthropic's API, AWS Bedrock, and Google Cloud's Vertex AI
Official APIs provide the most direct and reliable access but may present challenges for some users:
- Regional availability restrictions
- Complex payment requirements
- Account verification processes
- Higher standard pricing
Proxy Services: The laozhang.ai Option
For many users, proxy services like laozhang.ai offer significant advantages:
- Cost Savings: Typically 20-50% below official API pricing
- Simplified Access: Single API endpoint for multiple models
- Flexible Payment: Support for various payment methods including cryptocurrency
- Free Testing Credits: New users receive credits to evaluate both models
hljs javascript// Example of using laozhang.ai proxy to access both models
const axios = require('axios');
async function compareModels(prompt) {
const apiKey = 'your_laozhang_api_key';
const endpoint = 'https://api.laozhang.ai/v1/chat/completions';
// Gemini 2.5 Pro request
const geminiResponse = await axios.post(endpoint, {
model: 'gemini-2.5-pro',
messages: [{ role: 'user', content: prompt }],
temperature: 0.7
}, {
headers: {
'Content-Type': 'application/json',
'Authorization': `Bearer ${apiKey}`
}
});
// Claude 3.7 request
const claudeResponse = await axios.post(endpoint, {
model: 'claude-3-7-sonnet',
messages: [{ role: 'user', content: prompt }],
temperature: 0.7
}, {
headers: {
'Content-Type': 'application/json',
'Authorization': `Bearer ${apiKey}`
}
});
return {
gemini: geminiResponse.data,
claude: claudeResponse.data
};
}
💡 Testing Both Models
To determine which model works best for your specific use case, we recommend testing both with your actual prompts and data. Laozhang.ai provides free testing credits upon registration, making it easy to conduct head-to-head comparisons with your specific requirements.
Advanced Features and Unique Capabilities
Beyond the core metrics, each model offers unique capabilities worth considering:
Gemini 2.5 Pro Special Features
- Agent Mode: Can function as a persistent agent with memory and learning capabilities
- Function Calling: Robust support for calling external functions to extend capabilities
- Vision Language Models: Superior visual reasoning across diverse image types
- Code Interpreter: Built-in ability to execute and debug code in various languages
Claude 3.7 Sonnet Special Features
- Empathetic Responses: Better understanding of emotional context in conversations
- Constitutional AI: Built with ethical guardrails that reduce harmful outputs
- Extended Thinking: Transparent reasoning process that builds user trust
- Improved Factuality: Higher accuracy on factual queries with less hallucination
Frequently Asked Questions
Which model is better for coding?
Both models are exceptional for coding tasks. Gemini 2.5 Pro has a slight edge in algorithm optimization and backend development, while Claude 3.7 Sonnet excels in producing well-documented, maintainable code and frontend development. For most general coding tasks, either model will perform excellently.
How significant is the context window difference?
The context window difference (1M tokens for Gemini vs. 200K for Claude) is substantial for specific use cases like analyzing entire codebases, long research papers, or extensive documentation. For most common interactions and even many professional applications, Claude's 200K window is sufficient.
Is there a free tier for either model?
Neither model offers a true free tier at their highest capability levels. Google provides limited free access to Gemini Pro (not 2.5 Pro) with usage caps. The most cost-effective way to test both models is through proxy services like laozhang.ai, which offer free credits upon registration.
Can I switch easily between the models?
The models use different API formats, but proxy services like laozhang.ai provide a unified interface that makes switching between models relatively straightforward. With minimal code changes, you can implement A/B testing or model fallback strategies.
How much can I save using proxy services?
Savings through proxy services typically range from 20-50% compared to official API pricing. For high-volume applications, this can translate to thousands of dollars in monthly savings. Additionally, these services often offer volume discounts and promotional pricing not available through official channels.
Conclusion: Making Your Choice
Both Gemini 2.5 Pro and Claude 3.7 Sonnet represent the cutting edge of AI capabilities in 2025. Rather than declaring an overall winner, we recommend selecting the model that best aligns with your specific use case:
-
Choose Gemini 2.5 Pro if you need superior mathematical reasoning, multimodal capabilities, larger context windows, or more favorable pricing for high-volume applications.
-
Choose Claude 3.7 Sonnet if your priority is high-quality content creation, nuanced understanding of complex instructions, or applications where ethical considerations and tone management are paramount.
For many users, testing both models on your specific tasks is the most reliable way to determine which performs better for your unique requirements. With proxy services offering easy access to both models with free testing credits, conducting your own comparative evaluation has never been easier.
Register at laozhang.ai to receive free testing credits and compare both models on your specific tasks.
Update Log
hljs plaintext┌─ Update Record ───────────────────────────┐ │ 2025-05-10: Published with latest pricing │ │ 2025-05-08: Updated benchmark figures │ │ 2025-05-05: Initial draft completed │ └────────────────────────────────────────────┘