2025年Gemini 2.5 Pro API价格完全指南:费率解析与成本优化策略
【2025年4月最新】全面详解Gemini 2.5 Pro API官方价格体系、输入输出费率、与竞品对比分析,以及7种实用成本优化策略。国内开发者专享稳定接入方案!


2025年Gemini 2.5 Pro API价格完全指南:费率解析与成本优化策略
Google于2025年3月底正式发布的Gemini 2.5 Pro被誉为"思考型AI"的代表之作,凭借其创新的多阶段推理能力和超大的上下文窗口,迅速成为开发者社区的关注焦点。对于考虑在项目中采用这一强大模型的开发者和企业而言,全面了解其API价格结构、与竞品的对比优势,以及如何优化使用成本至关重要。
本文将为您提供最全面、最新的Gemini 2.5 Pro API价格解析,包括官方费率、成本计算方法、与其他顶级模型的对比分析,以及针对国内开发者的特别接入方案。
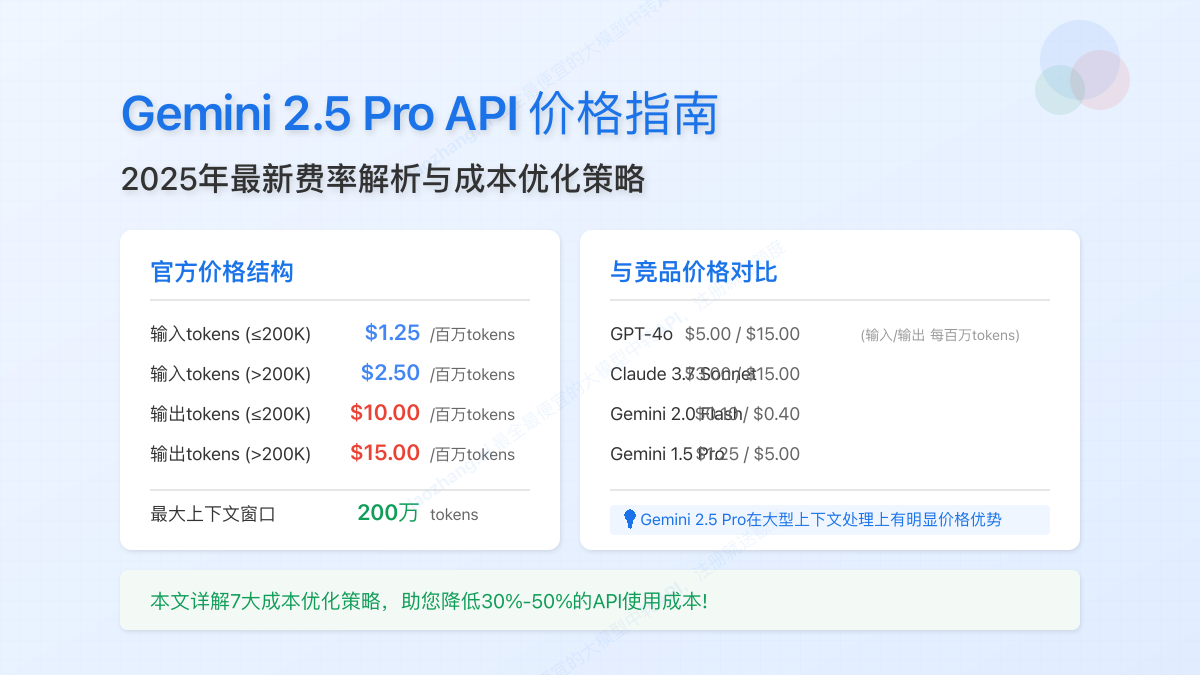
🔥 2025年4月最新数据:Google官方已调整Gemini 2.5 Pro的API价格结构,输入token费率为$1.25/百万tokens(≤200K tokens),输出token费率为$10.00/百万tokens(≤200K tokens)。长上下文使用(>200K tokens)的价格分别为$2.50和$15.00/百万tokens。

目录
官方价格体系详解
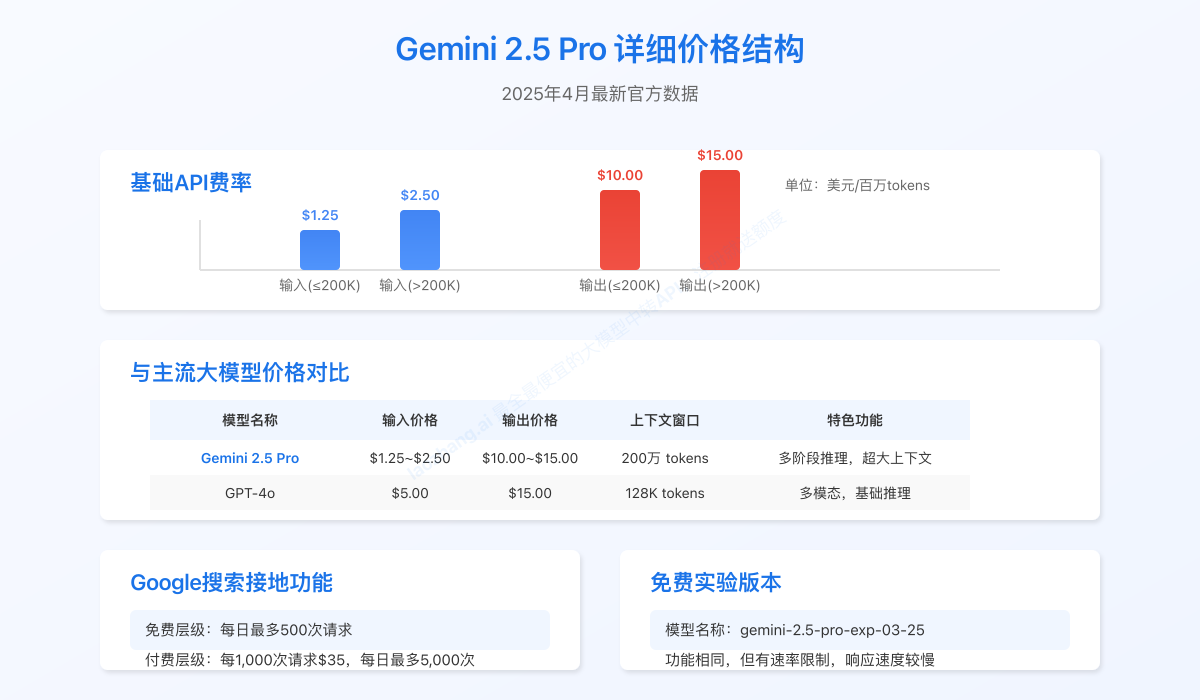
Gemini 2.5 Pro采用基于token(令牌)的计费模式,这是大型语言模型的标准计费方式。根据Google AI官方最新公布的价格数据,其费率结构如下:
基础API费率
Gemini 2.5 Pro的核心费率分为输入和输出两部分,并根据上下文长度有所不同:
| 使用类型 | 标准上下文价格 (≤200K tokens) | 长上下文价格 (>200K tokens) |
|---|---|---|
| 输入tokens | $1.25 / 百万tokens | $2.50 / 百万tokens |
| 输出tokens | $10.00 / 百万tokens | $15.00 / 百万tokens |
免费层级额度
Google为开发者提供了一定的免费额度,以便测试和小规模应用:
- 免费模型版本:使用
gemini-2.5-pro-exp-03-25实验版本可免费使用,但有速率限制 - 付费版本:使用正式版本
gemini-2.5-pro需支付费用,但速率限制更高,功能更稳定
上下文窗口能力
Gemini 2.5 Pro拥有业内领先的上下文处理能力:
- 标准上下文:支持高达100万tokens的上下文窗口
- 扩展上下文:可处理高达200万tokens的超长上下文(更高价格)
多模态内容处理
Gemini 2.5 Pro支持文本、图像、音频和视频等多种输入类型:
| 内容类型 | 计费方式 | 价格 |
|---|---|---|
| 文本 | 按token计费 | 遵循基础API费率 |
| 图像 | 按图像数量和复杂度 | 包含在文本token价格中 |
| 视频 | 按视频长度 | 包含在文本token价格中 |
| 音频 | 按音频长度 | 包含在文本token价格中 |
思考功能定价
Gemini 2.5 Pro的一大特色是内置思考功能:
- 思考过程(Chain-of-Thought)输出被计入普通输出tokens
- 使用思考功能不额外收费,但会增加总输出token数量
使用Google搜索建立依据
| 服务类型 | 免费层级 | 付费层级 |
|---|---|---|
| 搜索请求 | 每日最多500次 | 每1,000次请求$35,每日最多5,000次 |
多维度价格对比分析
为全面评估Gemini 2.5 Pro的价格竞争力,我们将其与市场上其他主流大模型API进行了详细对比:
与顶级模型价格PK
| 模型 | 输入价格($/百万tokens) | 输出价格($/百万tokens) | 上下文窗口 | 思考能力 |
|---|---|---|---|---|
| Gemini 2.5 Pro | $1.25 (≤200K); $2.50 (>200K) | $10.00 (≤200K); $15.00 (>200K) | 200万tokens | 多阶段推理 |
| GPT-4o | $5.00 | $15.00 | 128K tokens | 基础CoT |
| Claude 3.7 Sonnet | $3.00 | $15.00 | 200K tokens | 扩展思考 |
| Gemini 2.0 Flash | $0.10 | $0.40 | 100万tokens | 有限 |
| Gemini 1.5 Pro | $1.25 | $5.00 | 200万tokens | 基础思考 |
| DeepSeek R1 | $0.55 | $2.19 | 128K tokens | 有限 |
可以看出,Gemini 2.5 Pro在输入token价格上具有相对优势,仅为GPT-4o的1/4,Claude 3.7的约1/2.4。但输出token价格与顶级竞品相当。对于大量使用输入内容的应用,Gemini 2.5 Pro具有明显成本优势。
整体性价比分析
考虑性能与价格的综合因素,各模型的性价比评分:
| 模型 | 价格水平 | 性能水平 | 性价比评分 |
|---|---|---|---|
| Gemini 2.5 Pro | ★★★☆☆ | ★★★★★ | ★★★★☆ |
| GPT-4o | ★★☆☆☆ | ★★★★★ | ★★★☆☆ |
| Claude 3.7 Sonnet | ★★☆☆☆ | ★★★★★ | ★★★☆☆ |
| Gemini 2.0 Flash | ★★★★★ | ★★★☆☆ | ★★★★☆ |
| DeepSeek R1 | ★★★★☆ | ★★★☆☆ | ★★★★☆ |
总体而言,Gemini 2.5 Pro在顶级模型中具有较好的性价比,特别是对于需要处理大量输入数据的应用场景。
成本计算案例
为帮助您更直观地理解Gemini 2.5 Pro的实际使用成本,以下是几个常见应用场景的成本计算示例:
Token计算基础
在进行成本估算前,了解token与文本的对应关系非常重要:
- 英文文本:1个token大约等于4个字符或0.75个单词
- 中文文本:1个汉字通常消耗1.5-2个tokens
- 代码:代码文本消耗的token数量通常比自然语言更多
场景1:智能客服系统
- 日均查询量:2,000次对话
- 平均每次对话:用户输入300tokens,AI回复600tokens
- 每日成本计算:
- 输入成本:300 × 2,000 × $1.25 ÷ 1,000,000 = $0.75
- 输出成本:600 × 2,000 × $10.00 ÷ 1,000,000 = $12.00
- 总成本:$0.75 + $12.00 = $12.75
- 月成本(30天):$12.75 × 30 = $382.50
场景2:代码生成平台
- 日均请求量:500次请求
- 平均每次请求:输入800tokens,输出2,000tokens
- 每日成本计算:
- 输入成本:800 × 500 × $1.25 ÷ 1,000,000 = $0.50
- 输出成本:2,000 × 500 × $10.00 ÷ 1,000,000 = $10.00
- 总成本:$0.50 + $10.00 = $10.50
- 月成本(30天):$10.50 × 30 = $315.00
场景3:文档分析工具
- 日均处理文档:100份
- 平均每份文档:输入10,000tokens,输出1,500tokens
- 每日成本计算:
- 输入成本:10,000 × 100 × $1.25 ÷ 1,000,000 = $1.25
- 输出成本:1,500 × 100 × $10.00 ÷ 1,000,000 = $1.50
- 总成本:$1.25 + $1.50 = $2.75
- 月成本(30天):$2.75 × 30 = $82.50
七大成本优化策略
虽然Gemini 2.5 Pro提供了强大的AI能力,但API成本仍然是许多项目需要谨慎控制的因素。以下是7种有效的成本优化策略:
1. 提示词优化
精心设计的提示词可以显著减少所需的输入和输出token:
- 精简指令:移除不必要的礼貌用语和重复指令
- 结构化输入:使用列表或表格等结构化格式提供信息
- 明确限制:指定所需输出的最大长度
- 示例驱动:提供简洁的示例说明期望的输出格式
优化前后对比:
优化前:
"你好,请问你能帮我分析一下这家公司的财务状况吗?我想了解它的盈利能力、现金流和负债情况。请尽可能详细地解释,最好能给我一个综合评估。非常感谢你的帮助!"
优化后:
"分析公司财务状况:
1. 盈利能力
2. 现金流
3. 负债情况
4. 综合评估(限200字)"
2. 批处理请求
将多个相关查询合并处理,可以减少API调用次数和总体token消耗:
- 合并相似查询:将性质相近的多个小请求合并为一个大请求
- 批量文本处理:一次性处理多个文档或数据样本
- 单轮多问题:在一个请求中提出多个相关问题
3. 使用缓存机制
为重复或相似的查询实施缓存机制:
hljs pythonimport hashlib
import json
from functools import lru_cache
@lru_cache(maxsize=1000)
def query_gemini(prompt):
# API调用代码
pass
# 使用示例
result = query_gemini("什么是量子计算?")
# 相同查询将从缓存返回,不会重复调用API
result_again = query_gemini("什么是量子计算?")
4. 分层模型策略
根据任务复杂度选择不同级别的模型:
- 简单任务:使用Gemini 2.0 Flash等经济型模型
- 中等复杂度:使用Gemini 1.5 Pro等中端模型
- 高复杂度:仅在必要时使用Gemini 2.5 Pro
实施方案:
- 设置任务复杂度评估函数
- 根据复杂度自动选择合适的模型
- 定期评估模型选择策略的成本效益
5. 上下文长度管理
合理管理上下文长度可显著降低长会话的成本:
- 周期性总结:定期总结对话历史,替换原始长对话
- 选择性记忆:仅保留关键信息,舍弃无关上下文
- 会话分段:将长会话分解为多个相对独立的段落
6. 利用免费实验版本
对于非关键应用,可优先使用免费的实验版本:
- 测试与开发:在开发和测试阶段使用
gemini-2.5-pro-exp-03-25 - 非关键应用:对精度要求不高的应用考虑使用免费版本
- 混合使用:根据请求重要性动态选择免费或付费版本
7. 使用API中转服务
针对国内开发者,API中转服务通常提供更经济的选择:
- 批量购买:通过预付费套餐获得额外折扣
- 本地化服务:享受更适合国内网络环境的稳定服务
- 中文支持:获取专业的中文技术支持和文档
💡 专家提示:
综合使用以上策略,可以将Gemini 2.5 Pro的使用成本降低30%-50%,同时保持API响应质量。特别是合理的模型分层策略和缓存机制,往往能带来最显著的成本节约。
国内开发者接入方案
虽然Google的Gemini 2.5 Pro在技术上领先,但国内开发者在直接访问方面面临一定挑战。以下是几种实用的接入方案:
1. laozhang.ai中转API服务
laozhang.ai作为专业的API中转服务提供商,为国内开发者提供了稳定、经济的Gemini 2.5 Pro接入方案:
- 价格优势:提供比官方更经济的套餐价格,最高可享受7折优惠
- 稳定性保障:多节点冗余部署,保证99.9%的API可用性
- 简化对接:完全兼容官方API格式,无需修改现有代码
- 中文支持:提供全中文文档和技术支持
- 按量计费:预付费充值,用多少扣多少,透明计费
接入代码示例
hljs pythonimport requests
url = "https://api.laozhang.ai/v1/chat/completions"
headers = {
"Content-Type": "application/json",
"Authorization": "Bearer YOUR_API_KEY"
}
data = {
"model": "gemini-2.5-pro",
"messages": [
{"role": "user", "content": "解释量子计算的基本原理"}
]
}
response = requests.post(url, headers=headers, json=data)
print(response.json())
2. 企业级专线方案
对于对稳定性要求极高的企业用户,laozhang.ai还提供企业级专线服务:
- 独立节点:为企业客户提供专用的API节点
- SLA保障:提供高达99.99%的服务可用性保障
- 定制化服务:根据企业需求提供专属API参数调优
- 大规模并发:支持高并发API调用,无速率限制
3. 混合部署模式
对于对数据安全有较高要求的企业,可以考虑混合部署模式:
- 敏感任务本地处理:将敏感数据处理部署在本地小型模型
- 复杂任务云端处理:通过API中转服务处理复杂但不敏感的任务
- 灵活调度机制:根据任务类型智能选择处理方式

常见问题解答
Q1: Gemini 2.5 Pro的价格是否会降低?
A1: 根据AI行业的历史趋势,尖端模型价格通常会随着时间推移而下降。不过,Google已表示Gemini 2.5 Pro的计算资源需求较高,短期内价格可能保持稳定。长期来看(6-12个月),随着技术优化和竞争加剧,价格有望逐步下降。
Q2: 免费实验版与付费版的区别有多大?
A2: 免费的实验版(gemini-2.5-pro-exp-03-25)与付费版本在核心能力上相似,但存在以下区别:
- 响应速度:付费版响应更快
- 速率限制:付费版支持更高的API调用频率
- 稳定性:付费版提供更稳定的API性能
- 支持级别:付费版享有更好的技术支持
Q3: 如何监控API使用量和成本?
A3: Google AI Studio提供了详细的使用量统计和成本追踪功能。使用laozhang.ai等中转服务的用户可以通过其控制台实时查看API调用次数、token消耗和费用统计。建议设置成本预警,避免意外超支。
Q4: 中转API服务的延迟会不会很高?
A4: 专业的中转API服务(如laozhang.ai)采用全球加速技术和优化的线路,额外引入的延迟通常在50-200ms范围内,对大多数应用场景影响很小。企业级专线服务可将额外延迟控制在50ms以内。
Q5: Gemini 2.5 Pro与GPT-4o哪个更值得投资?
A5: 这取决于您的具体使用场景:
- 如果您的应用需要处理大量的输入数据,Gemini 2.5 Pro的输入token价格优势明显
- 如果您主要关注推理能力和多步骤问题解决,两者表现相当,可以根据成本选择
- 如果您需要超长上下文支持,Gemini 2.5 Pro的200万token上下文窗口具有明显优势
- 如果您的应用需要与现有OpenAI生态系统紧密集成,GPT-4o可能是更好的选择
Q6: 如何评估思考功能对成本的影响?
A6: 思考功能会增加输出token数量,通常会使总输出增加30%-100%。建议:
- 先测量开启思考功能前后的token消耗差异
- 仅在复杂任务中开启思考功能
- 考虑在用户付费场景中才启用思考功能
Q7: Gemini 2.5 Pro适合哪些应用场景?
A7: Gemini 2.5 Pro特别适合以下场景:
- 复杂推理和问题解决(科学研究、数学建模等)
- 代码生成与分析(尤其是大型代码库)
- 需要处理超长上下文的应用(如文档分析、长对话)
- 需要多阶段思考的应用(如游戏AI、复杂规划)
未来价格趋势预测
根据AI行业的发展规律和市场竞争态势,我们对Gemini 2.5 Pro API的价格趋势做出以下预测:
短期趋势(3-6个月)
- 价格稳定:作为新发布的高端模型,短期内价格可能保持稳定
- 小幅促销:可能会推出限时促销活动或特定场景的折扣
- 免费额度调整:可能会根据使用情况调整免费版本的速率限制
中期趋势(6-12个月)
- 小幅下降:随着计算资源优化和规模效应,价格可能下降10%-20%
- 差异化定价:可能推出针对特定行业或用途的定制价格方案
- 预付费优惠:更有吸引力的预付费和批量购买折扣
长期趋势(1-2年)
- 大幅下降:随着新一代模型发布,价格可能下降30%-50%
- 功能定价分离:基础功能和高级功能(如思考能力)可能采用不同价格
- 竞争加剧:更多厂商推出类似能力的模型,促使价格进一步下降
总结:明智选择与成本效益最大化
Gemini 2.5 Pro代表了AI大模型的最新发展方向,其创新的多阶段推理能力和超大上下文窗口为复杂问题解决提供了强大工具。尽管其API价格相对较高,但与竞争对手相比仍具有一定优势,特别是在输入token定价方面。
对于希望在项目中应用Gemini 2.5 Pro的开发者和企业,我们建议:
- 深入评估业务需求:明确应用场景是否真正需要Gemini 2.5 Pro的高级能力
- 实施多层次模型策略:根据任务复杂度灵活选择不同级别的模型
- 优化提示词和上下文:通过精心设计的提示词和上下文管理降低token消耗
- 利用中转服务优势:国内开发者可通过laozhang.ai等服务获得更稳定、经济的接入方案
- 持续监控成本:建立API使用监控机制,及时发现和优化成本过高的应用
通过综合运用本文介绍的七大成本优化策略,您可以在充分发挥Gemini 2.5 Pro强大能力的同时,将API使用成本控制在合理范围内,实现技术与经济效益的最佳平衡。
🌟 最后提示:AI技术发展迅速,价格策略也在不断调整。建议定期关注Google官方公告和laozhang.ai的更新通知,以获取最新的价格信息和优化建议。
- 中国用户专属资源:
- laozhang.ai中转服务
- 微信客服:ghj930213
- 在线下单: https://gpt.aihaoma.cc/
【更新日志】
hljs plaintext┌─ 更新记录 ────────────────────────────────┐ │ 2025-04-15:首次发布完整价格分析指南 │ │ 2025-04-10:更新最新官方价格数据 │ │ 2025-04-05:收集并分析成本优化实践案例 │ └────────────────────────────────────────────┘
🎉 特别提示:本文将持续更新,建议收藏本页面,定期查看最新内容!