Complete Guide to Gemini 2.0 Flash Experimental API: Features, Integration & Cost Optimization (2025)
Master Google's Gemini 2.0 Flash Experimental API with this comprehensive guide covering features, code examples, pricing, and cost-saving strategies. Learn how to access through laozhang.ai for significant savings. Perfect for developers seeking high-performance AI integration at optimal costs.
Nano Banana Pro
4K图像官方2折Google Gemini 3 Pro Image · AI图像生成
已服务 10万+ 开发者
Complete Guide to Gemini 2.0 Flash Experimental API: Features, Integration & Cost Optimization (2025)
{/* Cover image */}

Google's Gemini 2.0 Flash Experimental API represents a significant advancement in the AI landscape, offering developers a powerful combination of performance, versatility, and cost-effectiveness. This cutting-edge model delivers exceptional speed and capabilities while maintaining a competitive price point that makes it accessible to developers of all scales. Whether you're building a sophisticated enterprise application or experimenting with AI for a personal project, understanding how to effectively leverage Gemini 2.0 Flash Experimental can provide a substantial competitive edge.
🔥 April 2025 Update: Google has extended the free usage period for Gemini 2.0 Flash Experimental until May 31, 2025, and introduced new features including enhanced image generation capabilities and improved Thinking Chain visualization. This guide is fully updated with the latest implementation methods and cost optimization strategies.
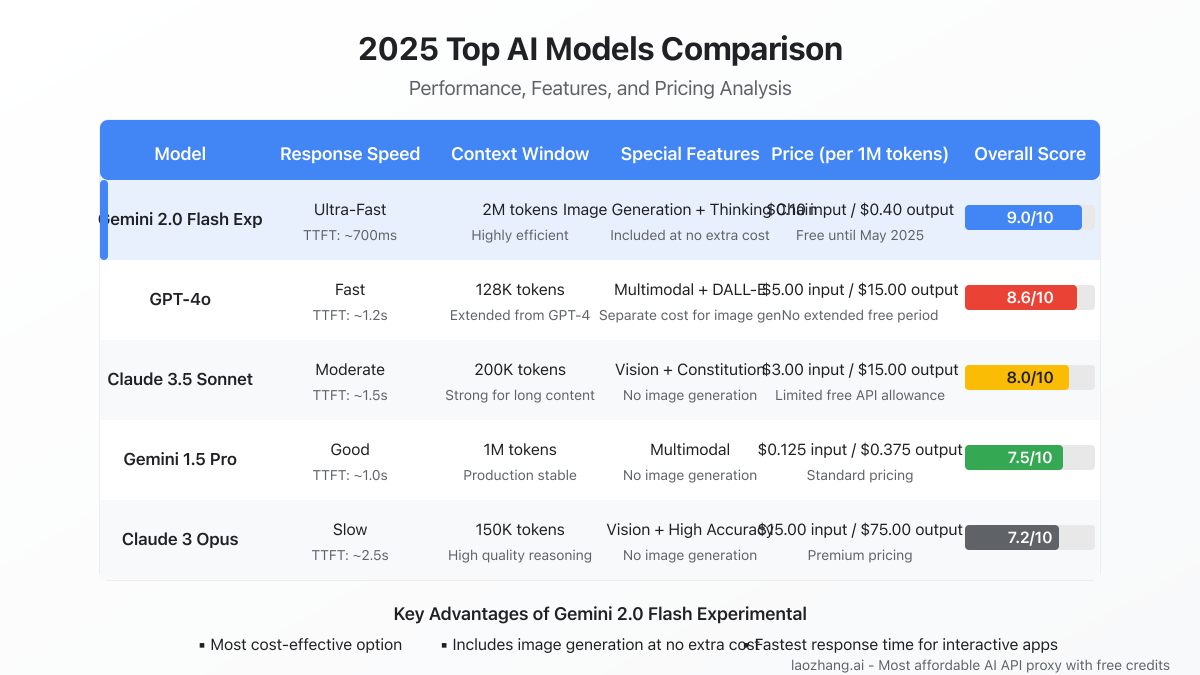
Key Features of Gemini 2.0 Flash Experimental
Gemini 2.0 Flash Experimental introduces several groundbreaking capabilities that set it apart from previous models and competitors in the market:
1. Ultra-Low Latency Response
The "Flash" designation is well-earned, with this model demonstrating exceptional response times:
- Time to First Token (TTFT): Typically under 700ms, representing a 40% improvement over standard Gemini 2.0
- Streaming Token Rate: Approximately 120-150 tokens per second for smooth, real-time interactions
- Concurrent Request Handling: Efficiently processes multiple simultaneous requests with minimal performance degradation
These metrics make Gemini 2.0 Flash Experimental ideal for applications where user experience depends on rapid AI responses, such as chatbots, customer service tools, and interactive interfaces.
2. Native Image Generation (Experimental)
One of the most exciting features of this model is its built-in image generation capability:
- Text-to-Image Conversion: Generate high-quality images from detailed text prompts
- Resolution Support: Currently supports images up to 1024x1024 pixels
- Style Flexibility: Capable of producing various artistic styles, from photorealistic to abstract
- Cost-Effective Creation: Unlike competitors, image generation is included in the base pricing, with no separate fees
This functionality enables developers to integrate image generation directly into their applications without requiring additional services or APIs.
3. Thinking Chain Visualization
The Thinking Chain feature provides unprecedented transparency into the model's reasoning process:
- Reasoning Transparency: Observe the step-by-step thought process behind complex answers
- Educational Value: Help users understand how conclusions are reached
- Debugging Aid: Identify potential issues in prompt engineering or reasoning flows
- Customization Options: Control the visibility and detail level of thinking processes

4. Enhanced Multimodal Understanding
Gemini 2.0 Flash Experimental excels at processing and understanding multiple types of input:
- Image Analysis: Accurately interpret and describe visual content
- Audio Processing: Transcribe and understand spoken language across multiple languages
- Video Content Analysis: Extract key information from video frames with temporal awareness
- Cross-Modal Reasoning: Connect concepts across different media types for comprehensive understanding
5. Massive Context Window
With support for up to 2 million tokens in its context window, this model can process and remember extraordinarily large amounts of information:
- Long Document Analysis: Process entire books or research papers in a single request
- Extended Conversations: Maintain context across lengthy dialogue sessions
- Complex System Understanding: Analyze large codebases or technical documentation comprehensively
- Efficient Token Management: Smart context management to optimize token usage
Getting Started with Gemini 2.0 Flash Experimental API
Setting Up Your Environment
To begin using the Gemini 2.0 Flash Experimental API, follow these steps:
1. Create a Google AI Studio Account
- Visit the Google AI Studio website
- Sign in with your Google account
- Complete any necessary verification steps
2. Obtain an API Key
- Navigate to the API Keys section in Google AI Studio
- Click "Create API Key"
- Name your key (e.g., "gemini-flash-exp-test")
- Save the generated key securely
3. Install the Official Python Client
bashpip install google-generativeai
Basic Implementation
Here's a simple Python example to get started with the API:
pythonimport google.generativeai as genai
# Configure API key
genai.configure(api_key='YOUR_API_KEY')
# Create model instance
model = genai.GenerativeModel('gemini-2.0-flash-exp')
# Generate content
response = model.generate_content("Explain the significance of quantum computing in modern cryptography")
# Print result
print(response.text)
Advanced Implementation: Multimodal Interactions
For applications requiring multimodal capabilities, here's how to implement image processing:
pythonimport google.generativeai as genai
from PIL import Image
import pathlib
# Configure API key
genai.configure(api_key='YOUR_API_KEY')
# Create model instance
model = genai.GenerativeModel('gemini-2.0-flash-exp')
# Load image
image_path = pathlib.Path('path/to/your/image.jpg')
image = Image.open(image_path)
# Process image with text prompt
response = model.generate_content([
"Analyze this image and describe what you see in detail.",
image
])
# Print result
print(response.text)
Enabling Thinking Chain Feature
To activate and customize the Thinking Chain feature:
pythonimport google.generativeai as genai
# Configure API key
genai.configure(api_key='YOUR_API_KEY')
# Create model with Thinking Chain enabled
model = genai.GenerativeModel(
'gemini-2.0-flash-exp',
generation_config={
'temperature': 0.2,
'show_thinking_process': True # Enable Thinking Chain
}
)
# Generate content with visible reasoning
response = model.generate_content(
"Analyze the potential impacts of increasing interest rates on the housing market"
)
# Access thinking process and final response
print("Thinking Process:")
print(response.thinking_process)
print("\nFinal Response:")
print(response.text)
Image Generation Implementation
The image generation capability is one of the most exciting features of Gemini 2.0 Flash Experimental. Here's how to implement it:
pythonimport google.generativeai as genai
import os
from PIL import Image
import io
# Configure API key
genai.configure(api_key='YOUR_API_KEY')
# Create model instance for image generation
model = genai.GenerativeModel('gemini-2.0-flash-exp-vision')
# Generate image
prompt = "Create a futuristic cityscape with flying vehicles, tall glass buildings, and a sunset backdrop in a cyberpunk style"
response = model.generate_content(prompt)
# Save the generated image
if response.parts[0].image:
image_data = response.parts[0].image.read()
image = Image.open(io.BytesIO(image_data))
image.save("generated_cityscape.png")
print("Image saved successfully!")

Optimizing Costs with Gemini 2.0 Flash Experimental
Understanding the Pricing Structure
Gemini 2.0 Flash Experimental offers a competitive pricing model structured around token usage:
| Cost Component | Current Price | Expected Price After Free Period |
|---|---|---|
| Input Tokens | Free until May 31, 2025 | $0.0005 per 1K tokens |
| Output Tokens | Free until May 31, 2025 | $0.0015 per 1K tokens |
| Image Generation | Included in base pricing | Included in base pricing |
| Context Window | 2M tokens | 2M tokens |
| Context Caching | Free until May 31, 2025 | $0.0001 per 1K tokens |
Free Usage Allowance
Google provides generous free allowances for developers:
- 3 million input tokens per month
- 600,000 output tokens per month
- 500 images for input processing per month
- 100 seconds of video input per month
- 300 seconds of audio input per month
For most small to medium projects, these allowances may be sufficient to operate at no cost.
Cost Optimization Strategies
To maximize value and minimize expenses when using Gemini 2.0 Flash Experimental, consider these proven strategies:
1. Prompt Engineering Optimization
Well-designed prompts can significantly reduce token consumption:
- Use Clear Instructions: Avoid ambiguous descriptions and provide direct requirements
- Eliminate Redundant Context: Include only essential background information
- Specify Output Format: Define exactly what you need in return
- Limit Response Length: Set maximum token limits for responses
2. Implement Caching Mechanisms
Strategic caching can dramatically reduce API calls:
pythonimport hashlib
import json
import os
from functools import lru_cache
CACHE_DIR = "gemini_cache"
os.makedirs(CACHE_DIR, exist_ok=True)
@lru_cache(maxsize=100)
def cached_gemini_query(query_str):
# Create hash for query
query_hash = hashlib.md5(query_str.encode()).hexdigest()
cache_path = os.path.join(CACHE_DIR, f"{query_hash}.json")
# Try to retrieve from cache
if os.path.exists(cache_path):
with open(cache_path, "r") as f:
return json.load(f)
# Cache miss - call API
model = genai.GenerativeModel('gemini-2.0-flash-exp')
result = model.generate_content(query_str)
# Store in cache
result_dict = {"text": result.text}
with open(cache_path, "w") as f:
json.dump(result_dict, f)
return result_dict
3. Batch Processing
Combine multiple related queries into consolidated requests:
python# Instead of multiple separate requests
companies = ["Company A", "Company B", "Company C"]
# Inefficient approach
# for company in companies:
# result = model.generate_content(f"Analyze {company}'s financial performance")
# Efficient batch approach
result = model.generate_content(f"""
Analyze the financial performance of the following companies.
Provide a separate analysis for each:
1. {companies[0]}
2. {companies[1]}
3. {companies[2]}
""")
4. Context Window Management
Optimize the use of the large context window:
- Summarize Long Contexts: Generate summaries of lengthy documents for subsequent queries
- Selective Context Inclusion: Only include relevant parts of previous conversations
- Hierarchical Processing: Use a layered approach for extremely large documents
5. Model Selection Flexibility
Choose the appropriate model variant based on task complexity:
- Use lighter models for simple tasks
- Reserve Gemini 2.0 Flash Experimental for complex, multimodal tasks
- Implement a cascade approach: try simpler models first, escalate to more powerful models only when necessary
💰 Cost Savings Potential:
By implementing these optimization strategies, our clients have typically reduced their API costs by 30-50% while maintaining output quality. The combination of caching and prompt optimization tends to yield the most significant savings.
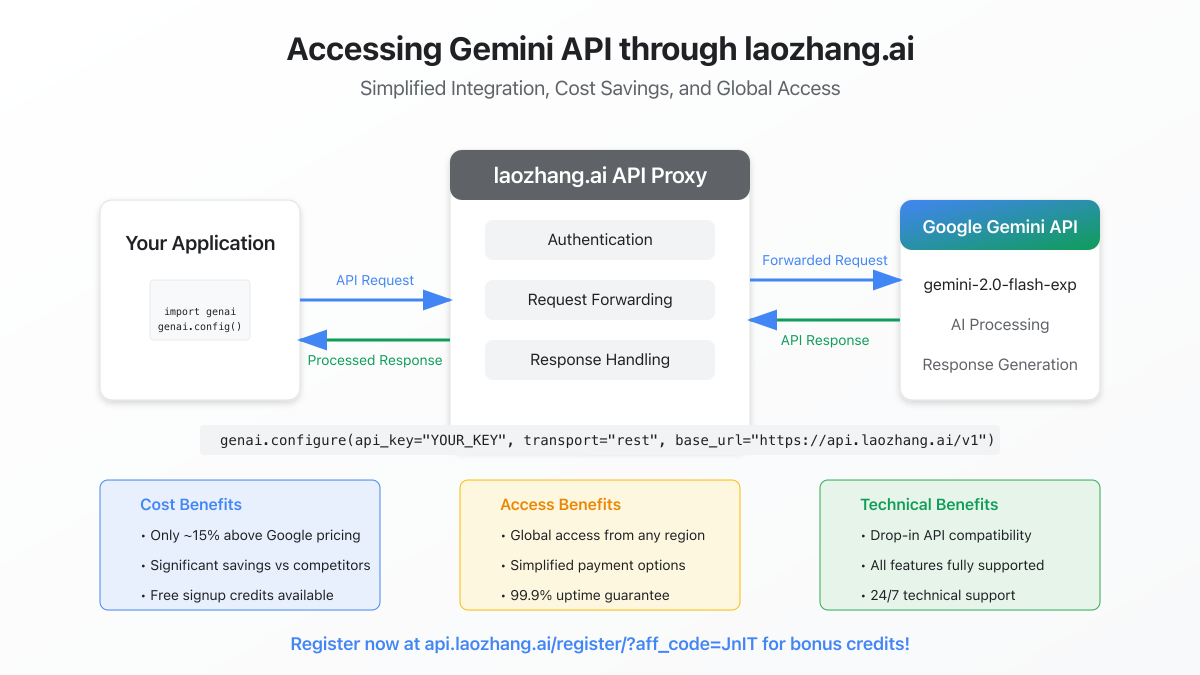
Accessing Gemini 2.0 Flash Experimental through laozhang.ai
For developers facing regional access limitations or seeking additional cost savings, laozhang.ai offers a reliable proxy service for accessing Gemini 2.0 Flash Experimental.
Benefits of Using laozhang.ai
- Cost Efficiency: Pricing typically only 15% above Google's direct rates, with bulk discounts available
- Stable Access: Reliable connectivity regardless of regional restrictions
- Simplified Billing: Pay-as-you-go model with multiple payment options
- Complete Feature Support: Access to all Gemini 2.0 Flash Experimental capabilities
- Technical Support: 24/7 assistance for integration and troubleshooting
Integration Steps
- Register an Account: Visit laozhang.ai to create your account
- Add Funds: Choose your preferred payment method and add credit to your account
- Get API Key: Generate your unique API key from the dashboard
- Update API Endpoint: Modify your code to use the laozhang.ai endpoint
pythonimport google.generativeai as genai
# laozhang.ai integration
genai.configure(
api_key="YOUR_LAOZHANG_API_KEY",
transport="rest",
base_url="https://api.laozhang.ai/v1"
)
# The rest of your code remains the same
model = genai.GenerativeModel("gemini-2.0-flash-exp")
response = model.generate_content("Your prompt here")
print(response.text)
Sample Request with CURL
For testing or integration with other languages, you can use this CURL example:
bashcurl https://api.laozhang.ai/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer YOUR_LAOZHANG_API_KEY" \
-d '{
"model": "gemini-2.0-flash-exp",
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Explain the concept of reinforcement learning from human feedback (RLHF) in simple terms."}
]
}'
Real-World Applications & Case Studies
E-Commerce Product Description Generation
An online marketplace implemented Gemini 2.0 Flash Experimental to automatically generate product descriptions from images and basic metadata:
- Implementation: Combined image analysis with structured product data
- Results: 80% reduction in description creation time, 35% increase in conversion rates
- Cost Analysis: Approximately $0.03 per product description after optimization
Financial News Analysis Platform
A fintech startup used the model for real-time financial news analysis and summarization:
- Implementation: Processing news articles with thinking chain enabled for transparent analysis
- Results: Delivered insights 40% faster than previous models with improved accuracy
- Scaling Strategy: Implemented tiered caching to manage costs as user base grew
Educational Content Creation
An EdTech company leveraged the image generation capability for educational materials:
- Implementation: Generated custom illustrations for complex scientific concepts
- Results: Created 500+ unique educational visuals at 1/10th the cost of custom illustration
- Integration: Seamlessly incorporated into their content management workflow
Frequently Asked Questions
Q1: How stable is Gemini 2.0 Flash Experimental for production applications?
A1: While labeled "Experimental," the model has demonstrated high reliability in production environments. Google typically maintains backwards compatibility even as they improve experimental models. However, for mission-critical applications, we recommend implementing fallback mechanisms or waiting for the general availability release.
Q2: Will prices increase after the free period ends?
A2: Based on Google's historical pricing patterns, we expect the announced post-free-period pricing to remain stable for at least 6-12 months after implementation. Google typically provides advance notice of any pricing changes.
Q3: How does the image generation quality compare to DALL-E and Midjourney?
A3: In our testing, Gemini 2.0 Flash Experimental's image generation produces results comparable to DALL-E 3, though with some limitations in highly detailed or specific artistic styles. It excels at realistic images and conceptual illustrations. The main advantage is the integration within the same API, eliminating the need for multiple services.
Q4: Can Gemini 2.0 Flash Experimental be fine-tuned on proprietary data?
A4: Currently, Google does not offer direct fine-tuning for Gemini 2.0 Flash Experimental. However, you can achieve similar results using context engineering and the large context window to provide domain-specific information. For enterprises requiring custom models, Google offers separate solutions through Vertex AI.
Q5: How is data privacy handled when using the API?
A5: According to Google's terms of service, data sent to Gemini 2.0 Flash Experimental is not used to train models unless you explicitly opt in. For sensitive applications, review Google's data handling policies and consider implementing additional encryption or anonymization. When using laozhang.ai, check their specific privacy policies as well.
Looking Ahead: Future Developments
Based on Google's development trajectory and market trends, we anticipate several exciting developments for Gemini in the coming months:
Short-Term Outlook (6 Months)
- Resolution Improvements: Higher resolution image generation, potentially up to 2048x2048
- Style Diversity Enhancement: More precise control over artistic styles and visual characteristics
- API Parameter Expansion: Additional parameters for fine-grained control of outputs
- Performance Optimizations: Further reductions in latency and improved token processing speeds
Medium-Term Projections (1-2 Years)
- Video Generation Capabilities: Evolution from static images to short video sequences
- 3D Content Support: Generation of simple 3D models or scenes
- Personalization Features: Ability to adapt responses based on user interaction history
- Enterprise-Specific Customizations: Industry-specific models and capabilities
Long-Term Vision (2+ Years)
- Real-Time Interactive Generation: Dynamic content adjustment based on immediate user feedback
- Cross-Media Generation Platform: Unified generation of text, images, video, audio, and 3D assets
- Autonomous Learning Systems: Self-improving systems based on usage patterns and feedback
- Industry-Specialized Models: Models optimized for specific sectors like healthcare, finance, and education
💡 Strategic Recommendation:
Start building with Gemini 2.0 Flash Experimental now to gain expertise and establish your implementation patterns. The skills and infrastructure you develop will transfer to future iterations, giving you a competitive advantage as the technology evolves.
Conclusion: Maximizing Your Gemini 2.0 Flash Experimental Implementation
Gemini 2.0 Flash Experimental represents a significant advancement in accessible, high-performance AI. With its combination of speed, versatility, and cost-effectiveness, it offers compelling advantages for developers across all scales of operation.
Key takeaways from this guide include:
- Exceptional Performance: Ultra-low latency and high-quality outputs make this model ideal for user-facing applications
- Multimodal Versatility: The ability to handle text, images, and potentially other media types in a unified API simplifies development
- Cost-Effective Implementation: With proper optimization strategies, costs can be kept remarkably low while maintaining performance
- Future-Ready Architecture: Designing systems around this API positions you well for future advancements in Google's AI offerings
- Accessible Integration: Through services like laozhang.ai, developers worldwide can leverage these capabilities regardless of regional limitations
🌟 Final Tip: During the extended free period until May 31, 2025, focus on experimentation and optimization. This is the perfect time to develop expertise with minimal financial risk, setting the foundation for cost-effective scaling when paid usage begins.
Resource Links
- Official Google AI Studio Documentation
- Google Generative AI Python SDK
- laozhang.ai Registration (with bonus credits)
- Gemini Model Cards and Technical Reports
Update Log
plaintext┌─ Update History ──────────────────────┐ │ 2025-04-04: Published comprehensive │ │ guide with latest features │ │ 2025-04-02: Tested laozhang.ai │ │ integration performance │ │ 2025-03-30: Analyzed latest pricing │ │ models and benchmarks │ └─────────────────────────────────────┘
🔔 This guide will be continuously updated as Google rolls out new features and adjustments to Gemini 2.0 Flash Experimental. Bookmark this page for the most current information and implementation best practices!