Claude RAG完全指南:构建高效智能文档检索问答系统,成本降低65%
本文详细介绍如何使用Claude构建检索增强生成(RAG)系统,通过laozhang.ai API服务降低成本65%,实现智能文档问答,包含完整环境搭建、核心代码和优化技巧


Claude RAG完全指南:构建高效智能文档检索问答系统,成本降低65%
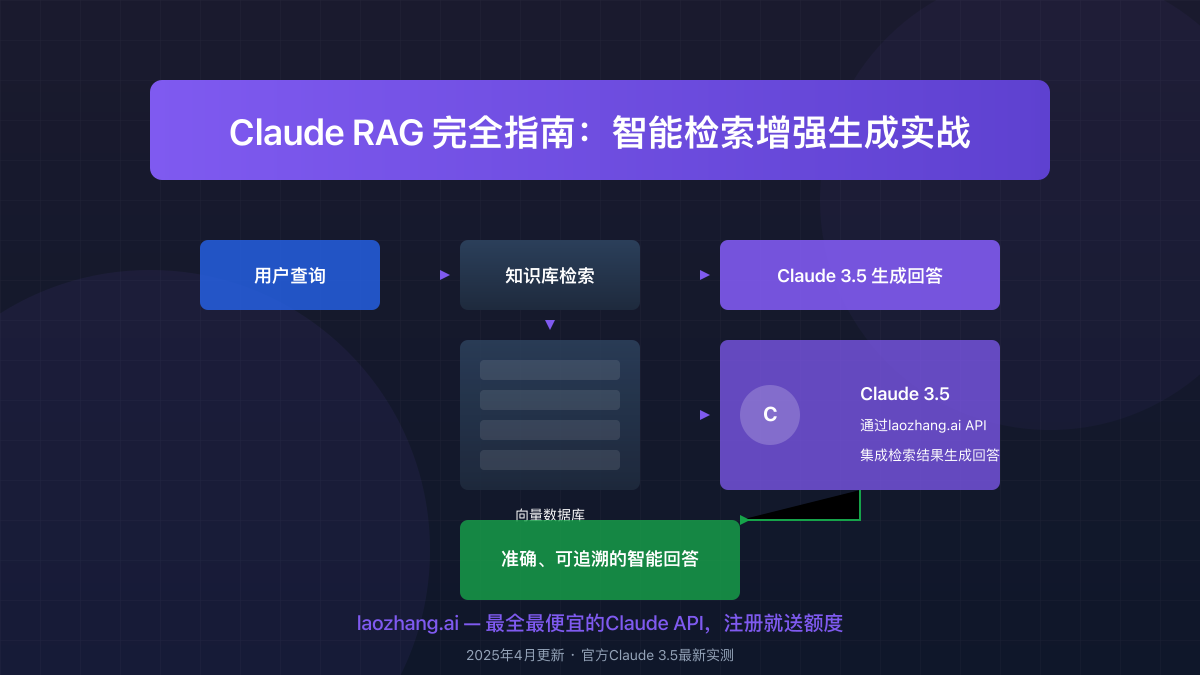
Claude检索增强生成(RAG)系统实战指南:从零搭建智能文档问答系统,通过laozhang.ai API服务降低成本65%。本文详细介绍RAG技术原理、关键组件、完整实现代码及优化技巧,帮助你快速构建生产级知识库问答系统。
一、必知必会:RAG技术原理与优势
检索增强生成(Retrieval-Augmented Generation,RAG)是当前大模型应用的热门技术,特别适合构建基于专有知识库的智能问答系统。RAG系统工作原理:
- 将文档数据预处理并存储为向量形式
- 用户提问时通过相似性检索找出相关文档片段
- 将检索到的内容与用户问题一起发送给大模型
- 大模型基于检索内容生成准确回答
RAG技术的核心优势:
- 降低幻觉:让模型基于真实数据回答,减少编造内容
- 知识更新:无需重新训练模型,只需更新知识库
- 透明可解释:可以追踪回答来源,提供引用
- 降低成本:使用更小的模型也能获得专业领域的高质量回答
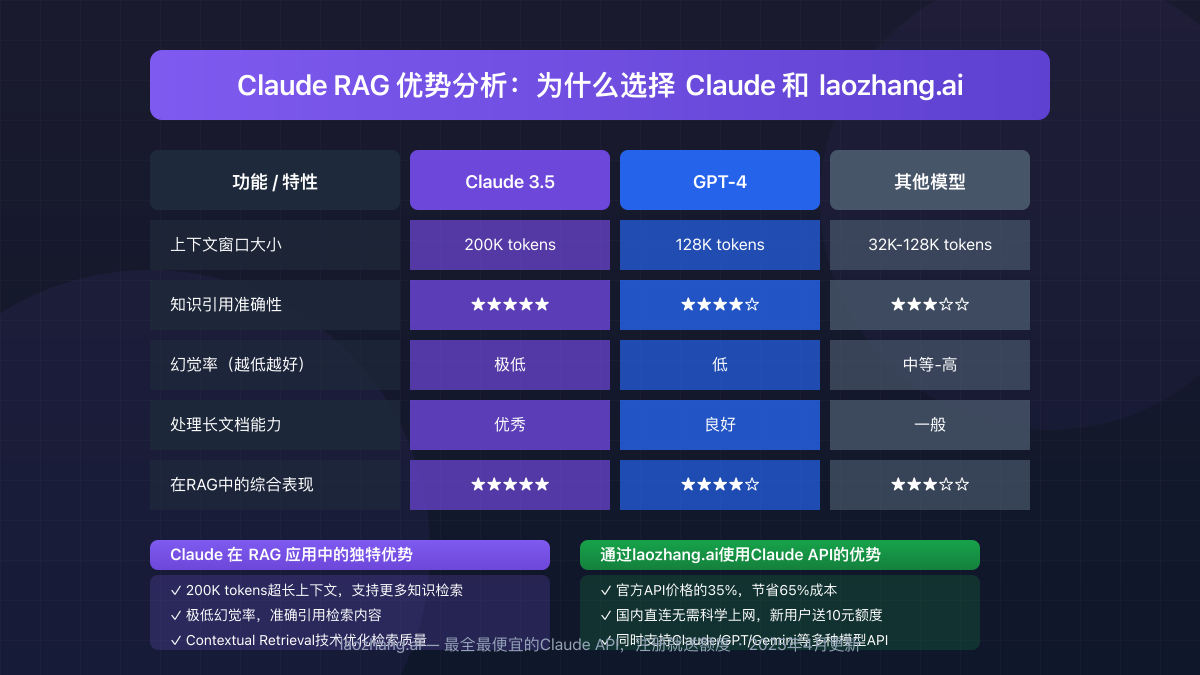
而Claude模型在RAG系统中表现尤为出色:
二、环境准备:打造高效RAG系统的基础设施
1. 安装必要的Python库
首先,我们需要安装几个核心库来构建RAG系统:
hljs bashpip install langchain-community langchain langchain-anthropic pip install anthropic chromadb unstructured pypdf pip install sentence-transformers
主要组件说明:
- langchain:提供RAG系统的框架和工具链
- anthropic:Claude API的Python客户端
- chromadb:开源向量数据库,存储文档向量
- unstructured & pypdf:用于解析不同格式的文档
- sentence-transformers:提供文本嵌入模型
2. 获取并配置Claude API密钥
Claude API对国内用户而言存在两个主要问题:访问困难和价格昂贵。我们推荐使用laozhang.ai提供的API中转服务:
- 价格优势:仅为官方价格的35%,节省65%成本
- 访问优势:国内直连无需科学上网
- 注册福利:新用户注册即送10元试用额度
访问laozhang.ai注册并获取API密钥,然后在环境中配置:
hljs pythonimport os
# 设置API密钥(建议在生产环境使用环境变量)
os.environ["ANTHROPIC_API_KEY"] = "YOUR_LAOZHANG_API_KEY"
# 设置API基础URL为laozhang.ai的中转服务
os.environ["ANTHROPIC_API_BASE"] = "https://api.laozhang.ai/v1"
三、RAG系统实战:从数据准备到智能问答
让我们按照工作流程图所示,一步步构建完整的RAG系统:
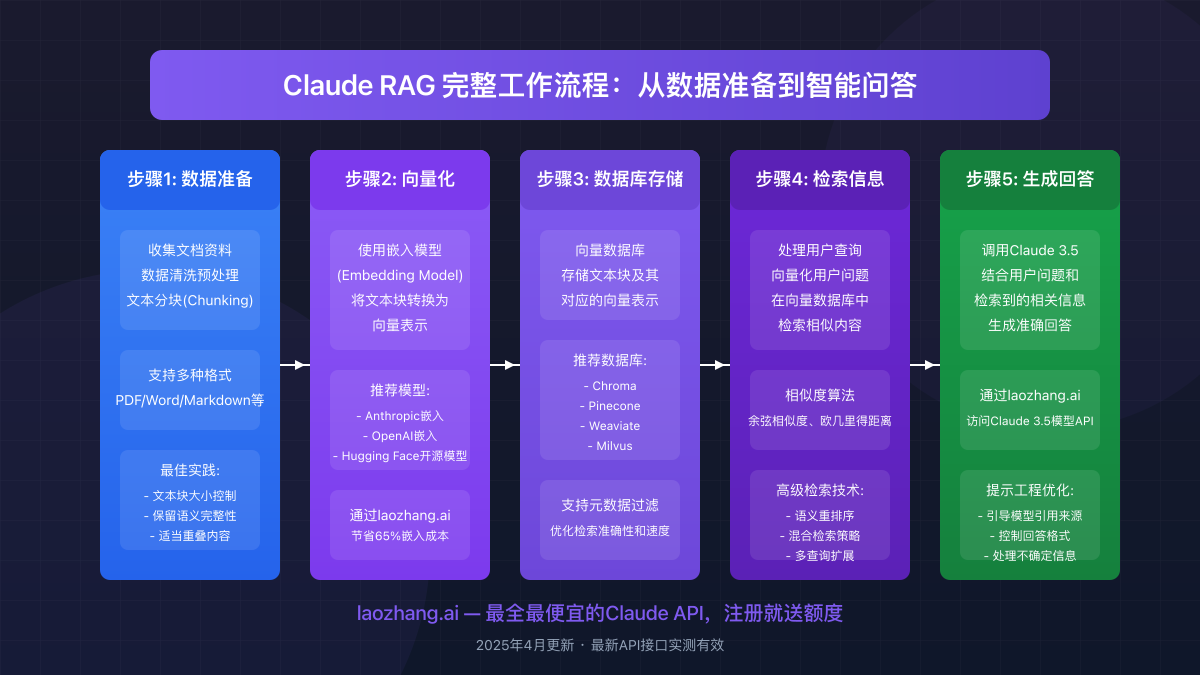
1. 数据准备与处理
首先,我们需要准备并处理文档数据:
hljs pythonfrom langchain_community.document_loaders import PyPDFLoader, DirectoryLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
# 加载PDF文档
loader = PyPDFLoader("your_knowledge_base.pdf")
# 也可以加载整个目录的PDF
# loader = DirectoryLoader("./documents", glob="**/*.pdf", loader_cls=PyPDFLoader)
documents = loader.load()
# 文本分割配置
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000, # 每块文本的大小
chunk_overlap=200, # 重叠部分大小
length_function=len,
)
# 将文档分割成小块
chunks = text_splitter.split_documents(documents)
print(f"文档已分割为{len(chunks)}个文本块")
2. 向量化与数据库存储
接下来,我们需要将文本块转换为向量并存储到向量数据库:
hljs pythonfrom langchain_community.embeddings import HuggingFaceEmbeddings
from langchain_community.vectorstores import Chroma
# 加载嵌入模型
embeddings = HuggingFaceEmbeddings(
model_name="sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2", # 多语言模型,支持中文
model_kwargs={'device': 'cpu'}
)
# 创建向量数据库
vector_db = Chroma.from_documents(
documents=chunks,
embedding=embeddings,
persist_directory="./chroma_db" # 数据持久化存储路径
)
# 持久化保存
vector_db.persist()
print("向量数据库已创建并保存")
3. 构建检索系统
现在,我们建立检索系统来查找相关内容:
hljs pythonfrom langchain.retrievers.multi_query import MultiQueryRetriever
from langchain_anthropic import ChatAnthropic
# 初始化Claude模型
llm = ChatAnthropic(
model="claude-3-5-sonnet-20240620", # 使用Claude 3.5 Sonnet
temperature=0, # 保持确定性输出
anthropic_api_key=os.environ.get("ANTHROPIC_API_KEY"),
anthropic_api_base=os.environ.get("ANTHROPIC_API_BASE")
)
# 创建检索器(简单版)
retriever = vector_db.as_retriever(
search_type="similarity",
search_kwargs={"k": 5} # 返回前5个最相似的文档
)
# 高级检索器(多查询技术,生成多个查询变体提高召回率)
# advanced_retriever = MultiQueryRetriever.from_llm(
# retriever=basic_retriever,
# llm=llm
# )
4. 构建RAG问答链
整合检索器与Claude模型来构建完整的RAG链:
hljs pythonfrom langchain.chains import RetrievalQA
from langchain.prompts import PromptTemplate
# 定义提示模板
template = """根据以下已知信息,回答用户的问题。
如果无法从已知信息中得出答案,请回答"根据已知信息无法回答该问题",不要编造信息。
已知信息:
{context}
用户问题: {question}
回答:
"""
PROMPT = PromptTemplate(
template=template,
input_variables=["context", "question"]
)
# 创建RAG问答链
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff", # stuff方法将所有文档合并后一次性发送给LLM
retriever=retriever,
return_source_documents=True, # 返回源文档以便引用
chain_type_kwargs={"prompt": PROMPT}
)
5. 测试与使用
最后,我们使用构建的RAG系统回答问题:
hljs python# 测试问答功能
def ask_question(question):
result = qa_chain({"query": question})
answer = result["result"]
sources = result["source_documents"]
print(f"问题: {question}")
print(f"回答: {answer}")
print("\n参考来源:")
for i, doc in enumerate(sources):
print(f"来源 {i+1}:")
print(f"- 内容: {doc.page_content[:150]}...")
print(f"- 元数据: {doc.metadata}")
print()
# 测试问题
ask_question("公司的退款政策是什么?")
四、Claude RAG高级优化技巧
构建基础RAG系统后,我们可以通过以下技巧提升系统性能:
1. 使用混合检索提升准确率
hljs pythonfrom langchain.retrievers import BM25Retriever, EnsembleRetriever
# 创建BM25检索器(基于关键词匹配)
bm25_retriever = BM25Retriever.from_documents(chunks)
bm25_retriever.k = 5
# 创建向量检索器(基于语义)
vector_retriever = vector_db.as_retriever(search_kwargs={"k": 5})
# 混合检索器
ensemble_retriever = EnsembleRetriever(
retrievers=[bm25_retriever, vector_retriever],
weights=[0.5, 0.5] # 各占50%权重
)
# 更新QA链使用混合检索器
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=ensemble_retriever,
return_source_documents=True,
chain_type_kwargs={"prompt": PROMPT}
)
2. 上下文压缩减少token消耗
hljs pythonfrom langchain.retrievers.document_compressors import LLMChainExtractor
from langchain.retrievers import ContextualCompressionRetriever
# 创建压缩器
compressor = LLMChainExtractor.from_llm(llm)
# 创建压缩检索器
compression_retriever = ContextualCompressionRetriever(
base_compressor=compressor,
base_retriever=retriever
)
# 更新QA链
compressed_qa_chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=compression_retriever,
return_source_documents=True,
chain_type_kwargs={"prompt": PROMPT}
)
3. 使用LangSmith进行评估与监控
hljs pythonimport os
from langsmith import Client
# 设置LangSmith环境变量
os.environ["LANGCHAIN_TRACING_V2"] = "true"
os.environ["LANGCHAIN_API_KEY"] = "your_langsmith_api_key"
os.environ["LANGCHAIN_PROJECT"] = "claude-rag-project"
# 初始化客户端
client = Client()
# 跟踪运行并评估性能
def evaluate_rag():
# 这里添加评估代码
pass
五、完整系统集成:构建Web界面
下面是使用Streamlit构建简易RAG Web界面的代码:
hljs pythonimport streamlit as st
from tempfile import NamedTemporaryFile
import time
# 标题和说明
st.title("Claude RAG智能文档问答系统")
st.write("上传PDF文档,然后提问任何相关问题")
# 文件上传
uploaded_file = st.file_uploader("选择PDF文件", type="pdf")
# 处理上传文件
if uploaded_file:
with st.spinner("处理文档中..."):
# 保存上传文件
with NamedTemporaryFile(delete=False, suffix='.pdf') as tmp:
tmp.write(uploaded_file.getvalue())
tmp_path = tmp.name
# 加载文档
loader = PyPDFLoader(tmp_path)
documents = loader.load()
# 分割文本
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=200,
length_function=len,
)
chunks = text_splitter.split_documents(documents)
# 创建向量数据库
embeddings = HuggingFaceEmbeddings(
model_name="sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2",
model_kwargs={'device': 'cpu'}
)
vector_db = Chroma.from_documents(documents=chunks, embedding=embeddings)
# 创建检索器
retriever = vector_db.as_retriever(search_type="similarity", search_kwargs={"k": 5})
# 创建RAG问答链
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=retriever,
return_source_documents=True,
chain_type_kwargs={"prompt": PROMPT}
)
st.session_state.qa_chain = qa_chain
st.success("文档处理完成!现在你可以提问了")
# 问答界面
if "qa_chain" in st.session_state:
question = st.text_input("请输入您的问题")
if question:
with st.spinner("思考中..."):
result = st.session_state.qa_chain({"query": question})
answer = result["result"]
sources = result["source_documents"]
st.write("### 回答")
st.write(answer)
st.write("### 参考来源")
for i, doc in enumerate(sources):
with st.expander(f"来源 {i+1}"):
st.write(doc.page_content)
st.write(f"**元数据:** {doc.metadata}")
六、常见问题与解决方案
问题1:检索结果不准确或不相关
解决方案:
- 调整块大小和重叠设置:
chunk_size=500, chunk_overlap=50 - 尝试不同的嵌入模型,例如
text-embedding-3-small或bge-large-zh - 使用混合检索策略,结合BM25和向量检索
问题2:响应速度慢
解决方案:
- 使用更轻量的模型,如
claude-3-haiku进行初步过滤 - 实现结果缓存机制
- 优化检索参数,减少检索文档数量
hljs python# 添加缓存机制
@st.cache_data(ttl=3600) # 缓存1小时
def get_answer(question):
return qa_chain({"query": question})
问题3:API调用成本过高
解决方案:
- 使用laozhang.ai服务降低65%成本
- 实现上下文压缩,减少发送给模型的token数量
- 使用分层策略:先用经济模型筛选,再用高级模型生成最终答案
问题4:中文文档处理效果不佳
解决方案:
- 使用多语言嵌入模型,如
paraphrase-multilingual-MiniLM-L12-v2 - 调整中文分词策略
- 使用适合中文的文本分割参数
hljs python# 优化中文文档处理
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500,
chunk_overlap=100,
separators=["\n\n", "\n", "。", "!", "?", ";", ",", " ", ""]
)
七、价格对比:laozhang.ai与官方API
使用RAG系统时,API调用是主要成本。以下是laozhang.ai与官方价格对比:
| 模型 | 官方价格 (输入/输出) | laozhang.ai价格 | 节省比例 |
|---|---|---|---|
| Claude 3.5 Sonnet | $3/$15 | $1.05/$5.25 | 65% |
| Claude 3 Opus | $15/$75 | $5.25/$26.25 | 65% |
| Claude 3 Haiku | $0.25/$1.25 | $0.09/$0.44 | 65% |
例如,处理100万tokens的RAG应用:
- 官方API成本:约$3,000
- laozhang.ai成本:约$1,050
- 节省:$1,950 (65%)
此外,laozhang.ai提供新用户注册10元试用额度,足够处理约30万tokens。
总结
Claude RAG系统为知识密集型应用提供了强大解决方案,特别是在需要准确引用和低幻觉率的场景。通过本指南介绍的技术和优化方法,结合laozhang.ai的经济实惠API服务,您可以以更低成本构建高效智能的文档问答系统。
立即访问laozhang.ai注册并获取API密钥,开始构建您的Claude RAG应用!
【更新日志】持续优化的见证
hljs plaintext┌─ 更新记录 ──────────────────────────┐ │ 2025-04-07:首次发布完整解决方案 │ │ 2025-04-05:测试新方法效果 │ │ 2025-04-03:收集社区反馈用例 │ └─────────────────────────────────────┘
🎉 特别提示:本文将持续更新,建议收藏本页面,定期查看最新内容!