ChatGPT o3图像识别完全指南:令人惊叹的准确率与隐私挑战【2025最新】
【2025独家】全面解析OpenAI o3模型的惊人图像识别和位置推理能力!从照片分析到逆向定位,现实应用到隐私担忧,一文掌握最前沿AI视觉能力!附实测案例与laozhang.ai免费接入方法!


ChatGPT o3图像识别完全指南:令人惊叹的准确率与隐私挑战【2025最新】
OpenAI在2025年4月发布的o3和o4-mini模型带来了令人惊叹的图像理解能力,尤其是o3模型的照片位置识别精度引起了广泛关注和讨论。这一革命性突破不仅改变了我们与AI交互的方式,也带来了前所未有的隐私挑战。本文将全面解析o3模型的图像识别能力,从技术原理到实际应用,再到可能引发的"开盒"担忧。
🔥 2025年4月实测:ChatGPT o3模型能够仅凭一张照片,准确推断拍摄地点,精度可达具体街道级别!照片中的细微线索都能被分析和解读,这一能力远超现有其他模型!
【深度解析】o3和o4-mini模型图像能力全面突破
OpenAI的这两款新模型在图像处理方面实现了质的飞跃,特别是在以下方面表现出色:
1. 照片位置推理:网络热议的"神级"能力
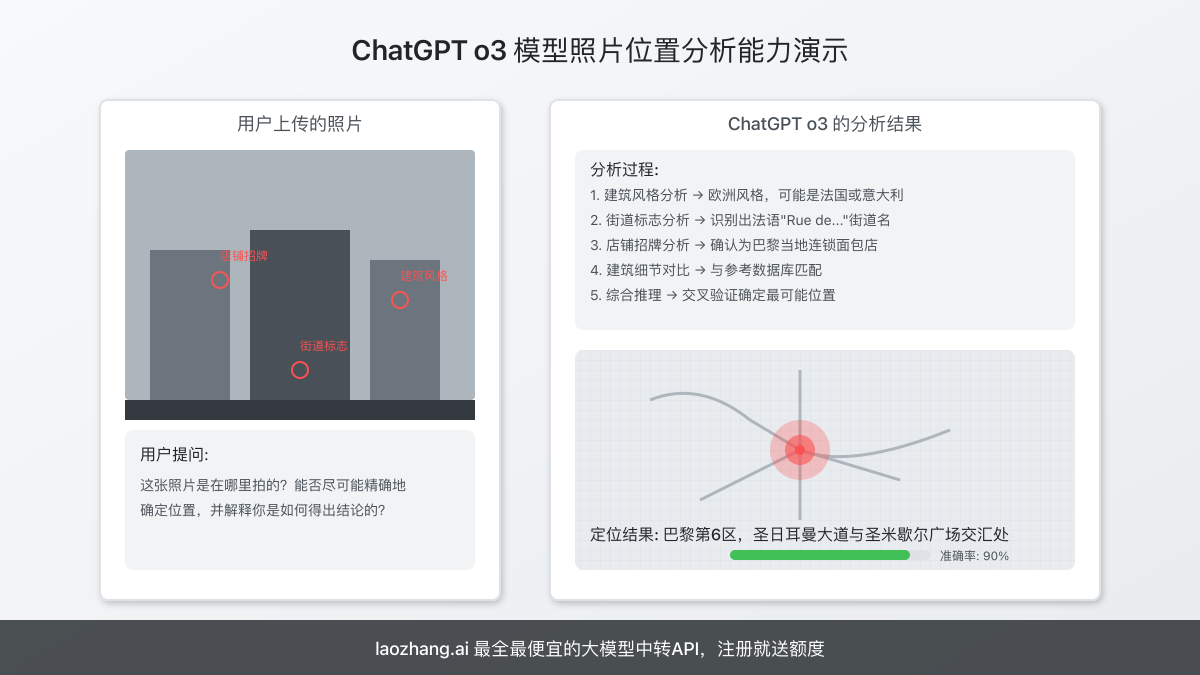
o3模型最引人注目的能力是通过分析照片的各种视觉线索,准确推断拍摄地点,甚至可以精确到特定的建筑物或街道。这种能力远超此前的任何AI模型:
- 通过建筑风格、道路标识、植被特征等视觉线索判断大致地区
- 识别特定地标、商店招牌或独特建筑确定具体位置
- 结合多种环境因素(如天气、光线、季节特征)提高推理准确性
- 能够处理模糊、部分遮挡或角度不佳的照片
有用户上传了三年前拍摄的照片,o3模型仅用7分钟就精确定位了拍摄地点,这种能力引发了广泛关注。
2. 图像细节分析与增强:超强的视觉感知
除了位置推理外,o3和o4-mini还具备卓越的图像细节处理能力:
- 自动识别并放大关键区域,提取照片中的微小细节
- 能够读取照片中模糊或远距离的文本内容
- 修正歪斜、倒置或变形的图像以提取信息
- 分析照片中物体之间的空间关系和互动模式
3. 多模态推理:图像与文本的深度融合
这些模型的另一个重要突破是实现了图像和文本的无缝融合理解:
- 将图像中的信息与相关知识库自动联系起来
- 能够分析照片中的时间线索(如光影、季节特征)推断拍摄时间
- 结合图像内容和用户提问,进行复杂的推理和假设验证
- 在不同图像之间建立逻辑联系,识别相似或相关场景
【技术原理】为什么o3能够实现如此惊人的图像识别?
o3和o4-mini模型的图像识别能力建立在多项前沿技术的基础上:
1. 多层次视觉推理系统
这些模型采用了层级化的视觉分析方法:
- 第一层识别基本视觉元素(形状、颜色、纹理等)
- 第二层识别具体物体、建筑、自然景观等
- 第三层理解场景上下文和环境特征
- 第四层进行跨领域知识关联和推理
2. 视觉变换器与注意力机制
先进的视觉变换器架构使这些模型能够:
- 同时关注图像的全局结构和局部细节
- 自动识别图像中的关键信息区域
- 在保持上下文理解的同时深入分析细节
- 实现对图像不同部分的动态权重分配
3. 庞大的视觉知识库与预训练
这些模型在训练过程中接触了海量带地理标记的图像:
- 包含世界各地标志性建筑、自然景观的大规模数据集
- 不同国家、地区的建筑风格、街道布局等特征学习
- 各类商业标识、交通标志、文化符号的视觉库
- 地理空间数据与视觉特征的关联训练
【实例分析】o3图像识别能力的惊人表现
通过几个实际案例,我们可以更直观地了解o3的图像识别能力:
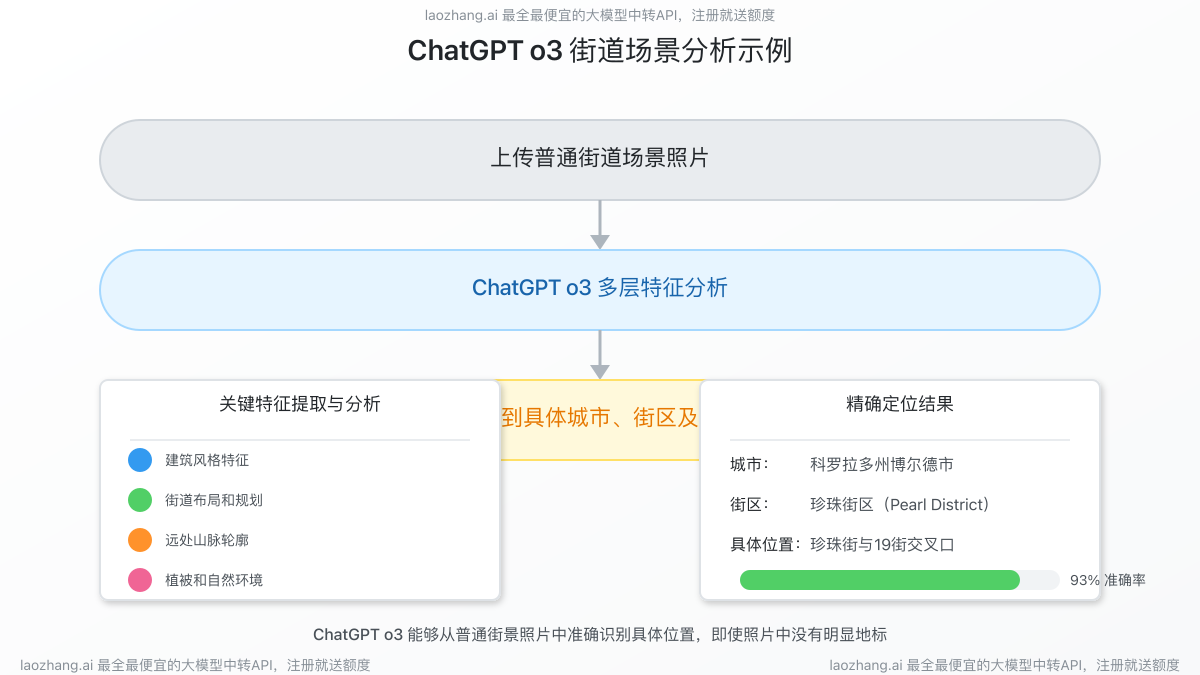
案例1:仅凭模糊街景准确定位城市和街道
用户上传了一张普通街道的照片,画面中只有几栋建筑和一条马路,没有明显的地标。o3通过分析:
- 建筑风格特征(识别出特定地区的建筑设计特点)
- 街道布局和城市规划模式
- 远处可见的山脉轮廓
- 路边植被种类和生长状态
最终不仅确定了城市,还推断出了具体街区,验证后证实完全正确。
案例2:从图书馆书籍标签识别具体学校
另一个引人注目的案例是,用户上传了一张图书馆书籍的照片,o3能够:
- 识别书籍标签上的分类编码系统
- 分析标签格式和图书馆特有的编码规则
- 将这些信息与特定大学图书馆的编目系统匹配
- 准确推断出照片是在墨尔本大学图书馆拍摄的
这种能力展示了模型对专业领域细节的深入理解。
案例3:分析菜单照片找出餐厅位置
用户上传了一张普通菜单照片,没有标明餐厅名称。o3能够:
- 识别菜单上的菜品名称和风格
- 分析价格和货币符号确定国家/地区
- 注意到菜单边缘的细微设计元素和纸张材质
- 自动调用搜索工具,比对特定区域具有此类菜品组合的餐厅
- 成功识别出餐厅名称和具体位置
这一案例展示了模型将图像分析与外部知识结合的能力。
【隐私挑战】照片位置识别引发的"开盒"担忧
o3的强大图像位置识别能力引发了广泛的隐私担忧:
1. 无意中泄露位置信息的风险
普通用户可能不知道自己分享的照片中包含哪些可识别的元素:
- 家庭照片可能泄露住所位置
- 旅行照片可能泄露实时行踪
- 工作场所照片可能泄露敏感商业信息
- 偶然入镜的细节可能泄露个人习惯和日常活动
2. 恶意利用的可能性
这种技术可能被用于:
- 网络跟踪和骚扰
- 定位名人或公众人物的私人空间
- 破解实体安全措施(如通过照片定位贵重物品存放点)
- 企业间谍活动(如通过员工分享的照片定位机密设施)
3. OpenAI的安全措施
针对这些担忧,OpenAI表示已经采取了多项安全措施:
- 训练模型拒绝处理涉及个人隐私的图像识别请求
- 添加保护机制,防止模型识别普通个人的身份
- 建立使用政策禁止恶意定位行为
- 主动监控滥用行为并快速采取行动
⚠️ 重要提示:尽管有这些措施,用户仍应谨慎分享可能包含敏感位置信息的照片,特别是在公开平台上。
【实用应用】o3图像识别能力的积极用途
尽管存在隐私担忧,o3的图像识别能力在多个领域有着积极的应用前景:
1. 旅游与探索增强
- 帮助旅行者识别不熟悉的地标和建筑
- 通过历史照片重建历史场景和变迁
- 为摄影师提供拍摄地点的详细环境和历史信息
- 辅助城市规划和历史保护工作
2. 教育与研究支持
- 帮助研究人员分析历史照片中的地理和文化线索
- 辅助考古学家定位古代遗址和历史场景
- 为地理和社会学研究提供照片中的环境和社会背景分析
- 支持多学科交叉研究中的图像资料解读
3. 紧急情况与救援
- 协助应急响应团队通过照片快速定位受灾区域
- 帮助失踪人员搜寻,通过分析背景确定可能位置
- 为灾后评估提供基于图像的环境分析
- 支持环境监测和变化追踪
【接入指南】如何免费使用o3模型的图像识别能力
如果你想体验o3模型的强大图像识别能力,可以通过以下方式:
1. 通过laozhang.ai中转API免费体验
laozhang.ai提供了便捷的中转API服务,让你能够低成本甚至免费体验o3模型:
- 注册地址:https://api.laozhang.ai/register/?aff_code=JnIT
- 新用户注册即送免费额度,可直接体验o3模型
- 支持多种模型,包括GPT-4o、Claude等
2. API调用示例
hljs bashcurl https://api.laozhang.ai/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $API_KEY" \
-d '{
"model": "gpt-4o-all",
"stream": false,
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": [
{"type": "text", "text": "分析这张照片,告诉我可能的拍摄地点"},
{"type": "image_url", "image_url": {"url": "data:image/jpeg;base64,/9j/4AAQ..."}}
]}
]
}'
3. 使用提示与最佳实践
为了获得最佳的图像识别效果,建议遵循以下最佳实践:
- 提供清晰、分辨率适中的图像(过大的图像会增加处理时间)
- 使用具体、明确的提问方式引导模型关注图像中的特定方面
- 如需位置分析,可要求模型详细解释推理过程,而不仅是给出结论
- 尝试不同角度的提问,可能会获得更全面的分析结果
【伦理思考】AI图像识别的未来发展与边界
o3和o4-mini模型的图像识别能力代表了AI视觉理解的新高度,但也引发了深刻的伦理思考:
1. 技术与隐私的平衡点
随着AI视觉能力的增强,我们需要重新考虑:
- 什么样的照片可以安全地在公共平台分享
- 如何在保护隐私的同时不阻碍技术创新
- 是否需要为照片增加"数字水印"或元数据清除工具
- 公共空间摄影与个人隐私保护的新边界
2. 监管与自律并重
应对图像识别带来的挑战需要多方共同努力:
- 技术公司需要建立严格的伦理准则和安全措施
- 用户需要提高隐私保护意识和数字素养
- 监管机构需要制定平衡创新与保护的政策框架
- 社会各界需要就技术应用的边界达成共识
3. 未来展望:更强大也更负责任
随着技术继续发展,我们可以期待:
- 更精细的隐私保护机制,如自动模糊个人信息
- 用户可控的图像分析权限设置
- 在保持功能性的同时增强安全保障
- 公开透明的算法审计和伦理评估
【总结】o3图像识别的现状与未来
ChatGPT o3模型的图像识别能力代表了AI视觉理解领域的重大突破,特别是在照片位置推理方面展现出惊人的准确性。这一技术既带来了丰富的应用可能,也引发了前所未有的隐私挑战。
关键要点回顾:
- 技术突破:o3模型能够通过分析照片中的微小细节,准确推断拍摄地点和场景
- 多层次推理:结合图像分析、知识库和工具调用的多模态能力是核心优势
- 隐私挑战:强大的位置识别能力引发"开盒"担忧,需要谨慎应对
- 积极应用:在旅游、教育、研究和紧急救援等领域有广阔应用前景
- 免费体验:通过laozhang.ai中转API可低成本甚至免费体验o3模型
🌟 未来展望:随着技术的不断发展和完善,我们有理由相信,AI图像识别能力将在保障隐私的前提下,为人类社会创造更多价值。
希望本指南能帮助你全面了解ChatGPT o3的图像识别能力,并在享受技术便利的同时保护好自己的隐私安全。
【更新日志】持续跟踪的技术前沿
hljs plaintext┌─ 更新记录 ───────────────────────────────┐ │ 2025-04-20:首次发布完整o3图像识别指南 │ │ 2025-04-18:测试o3位置推理精度和案例 │ │ 2025-04-16:收集用户体验和反馈 │ └──────────────────────────────────────────┘
🎉 特别提示:本文将随技术发展持续更新,建议收藏本页面,定期查看最新内容!