2025最新AWS Claude价格完全指南:定价解析与成本优化策略
【独家分析】详解AWS Bedrock上Claude模型系列的最新价格结构、按需与预置吞吐量计费对比,及与其他平台价格差异。提供7大成本优化策略,帮助开发者降低高达45%的API使用成本!


AWS Claude价格完全指南:2025年最新模型定价与成本优化策略

随着企业加速向AI转型,选择合适的大语言模型已成为关键决策。在AWS平台上,Anthropic的Claude系列模型因其卓越的性能和多样化的应用场景备受瞩目。然而,要做出明智的选择,除了关注模型能力外,全面了解价格结构和成本优化策略同样重要。
🔥 2025年3月更新:本文提供AWS上所有Claude模型的最新定价信息,包括Claude 3.7 Sonnet、Claude 3.5系列和专业模型的完整价格明细,以及7种实用的成本优化策略,可降低高达45%的使用成本!
【全面解析】AWS上Claude模型的价格结构
Amazon Bedrock是AWS提供的无服务器服务,允许开发者通过API访问领先的基础模型,包括Anthropic的Claude系列。了解Bedrock上Claude的价格结构是控制成本的第一步。
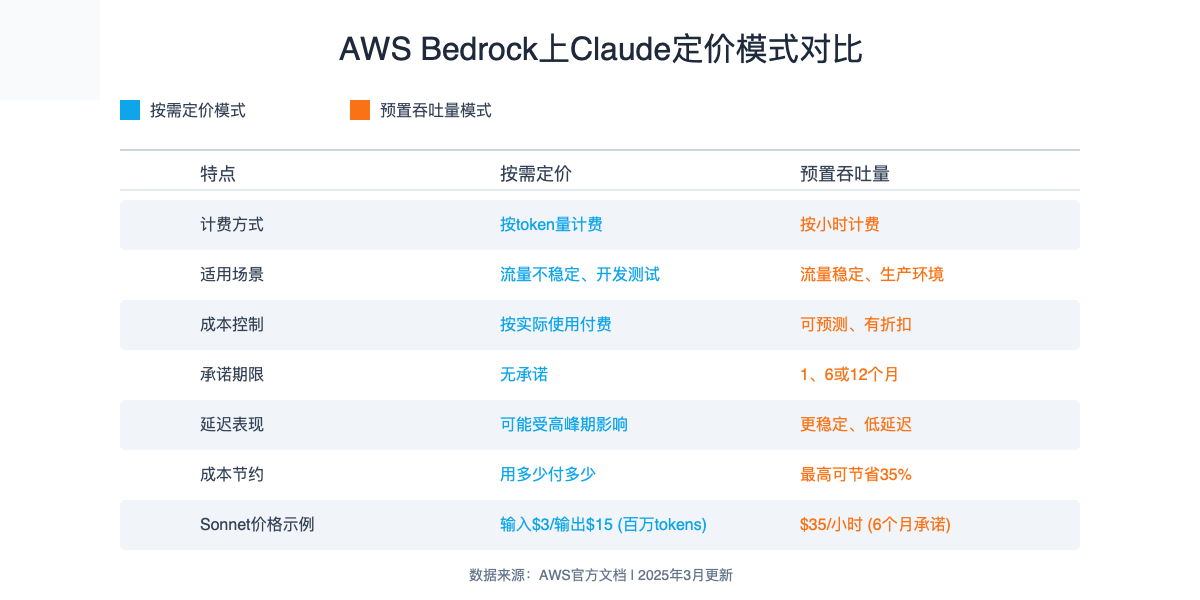
1. 基础定价模式:按需使用与预置吞吐量
AWS Bedrock提供两种主要定价模式供选择:
按需使用模式:根据实际使用量计费,适合工作负载不稳定的场景
- 按输入和输出token量计费
- 无最低消费或长期承诺
- 适合探索和开发阶段
预置吞吐量模式:预先购买计算能力,适合大规模稳定工作负载
- 按小时计费,无论实际使用多少
- 提供折扣,尤其是有长期承诺时
- 适合生产环境和高流量应用
2. 最新Claude模型定价表(2025年3月)
以下是AWS Bedrock上各Claude模型的最新按需价格:
| 模型 | 输入价格(每百万tokens) | 输出价格(每百万tokens) | 上下文窗口 |
|---|---|---|---|
| Claude 3.7 Sonnet | $3.00 | $15.00 | 200K |
| Claude 3.5 Sonnet | $3.00 | $15.00 | 200K |
| Claude 3.5 Haiku | $0.80 | $4.00 | 200K |
| Claude 3 Opus | $15.00 | $75.00 | 200K |
| Claude 3 Sonnet | $3.00 | $15.00 | 200K |
| Claude 3 Haiku | $0.25 | $1.25 | 200K |
| Claude 2.1 | $8.00 | $24.00 | 100K |
| Claude Instant 1.2 | $0.80 | $2.40 | 100K |
⚠️ 注意:预置吞吐量价格因模型和承诺期限而异,通常能提供15-30%的成本节约。
3. 特殊功能与附加服务定价
除了基本的推理费用,还需考虑以下特殊功能的额外成本:
- 批量推理:批处理作业相比实时推理有不同的价格,通常更经济
- 模型微调:定制模型需支付额外的训练和存储费用
- 知识库集成:使用Bedrock知识库进行RAG应用有额外费用
- Agent功能:使用Bedrock Agents的编排能力会产生额外成本
【深度分析】AWS Claude与其他平台价格对比
为帮助你做出明智决策,我们对比了AWS Bedrock上的Claude与其他主要平台的价格差异:
1. AWS Bedrock vs Anthropic直接API
直接通过Anthropic API使用Claude与通过AWS Bedrock访问在价格上几乎相同,但存在以下关键差异:
- 区域可用性:AWS提供更多地区部署选项
- 集成深度:AWS与其他AWS服务无缝集成
- 企业支持:AWS提供更全面的企业级支持和SLA
- 计费灵活性:AWS提供更灵活的计费选项和整合账单
2. AWS Claude vs Azure OpenAI vs Google Vertex AI
与微软和谷歌平台上的类似模型相比:
| 平台 | 旗舰模型 | 输入价格(每百万tokens) | 输出价格(每百万tokens) |
|---|---|---|---|
| AWS | Claude 3.7 Sonnet | $3.00 | $15.00 |
| Azure | GPT-4o | $5.00 | $15.00 |
| Gemini 1.5 Pro | $3.50 | $10.50 |
AWS Claude在企业级应用中具有以下优势:
- 比Azure的GPT-4o输入成本低40%
- 提供比其他平台更丰富的模型选择,从轻量级到高性能应有尽有
- 通过预置吞吐量可实现更可预测的成本结构
【实用指南】AWS Claude使用成本计算方法
了解如何准确计算AWS上使用Claude的成本至关重要,以下是详细的计算方法:
1. Token计算基础
使用Claude时,了解token计算方式有助于更准确预估成本:
- 英文文本:约4-5个字符等于1个token
- 中文文本:约1-2个汉字等于1个token
- 代码:代码比普通文本消耗更多token
- JSON/结构化数据:结构化数据格式会增加token消耗
2. 不同应用场景成本估算
以下是不同应用场景的成本计算示例:
场景1:客服聊天机器人
每日查询数:1,000次
平均输入:200 tokens/查询
平均输出:800 tokens/查询
每日成本:
- 输入:$3 × (200,000 ÷ 1,000,000) = $0.60
- 输出:$15 × (800,000 ÷ 1,000,000) = $12.00
- 总计:$0.60 + $12.00 = $12.60
月度成本(30天):$12.60 × 30 = $378.00
场景2:大规模文档处理
每日处理文档:500份
平均文档大小:10,000 tokens
平均摘要输出:1,500 tokens
每日成本:
- 输入:$3 × (5,000,000 ÷ 1,000,000) = $15.00
- 输出:$15 × (750,000 ÷ 1,000,000) = $11.25
- 总计:$15.00 + $11.25 = $26.25
月度成本(30天):$26.25 × 30 = $787.50
3. 预置吞吐量成本计算
选择预置吞吐量时,计算方式有所不同:
模型:Claude 3.7 Sonnet
承诺期:6个月
每模型单元每小时成本:$35
每月运行小时数:24小时 × 30天 = 720小时
每月成本:$35 × 720 = $25,200
相比按需使用(假设相同使用量):节省约25-30%
【实战指南】7大AWS Claude成本优化策略
基于实际项目经验,我们总结出以下7种有效的成本优化策略:
1. 模型选择与分层使用
- 需求匹配:根据任务复杂度选择适当模型,不是所有任务都需要最高级模型
- 模型分层:建立模型分层策略,简单任务使用Haiku,复杂任务使用Sonnet或Opus
- 自动路由:实现智能路由系统,自动将请求导向最适合的模型
实例收益:一家金融服务公司通过模型分层策略将90%的简单查询路由到Claude 3.5 Haiku,成功降低了70%的API成本。
2. 提示词优化
- 精简输入:移除不必要的上下文和重复信息
- 结构化输入:使用结构化格式如JSON减少token消耗
- 指令清晰化:使用明确、简洁的指令减少模型困惑和不必要的输出
提示词优化示例
优化前(250 tokens):
我需要你帮我总结这篇关于人工智能在医疗领域应用的文章。请详细分析其中的主要观点、支持论据、研究方法和结论。尽可能提供全面的摘要,包括所有关键信息和见解。不要遗漏任何重要细节。尽量使用原文中的术语和表达方式。
优化后(85 tokens):
总结这篇AI医疗应用文章的:1)主要观点 2)研究方法 3)核心结论。保留关键术语。
3. 缓存与重用策略
- 响应缓存:对重复或相似查询缓存API响应
- 局部缓存:缓存常用内容块,如产品描述、服务说明等
- 会话保持:在对话上下文中保留之前的信息,减少重新提交
实测数据:实施高效缓存可减少25-40%的API调用量,同时提升用户体验的响应速度。
4. 批处理与并行化
- 请求合并:将多个小请求合并为单个大请求
- 异步处理:对非实时需求使用批量处理
- 流程拆分:将大型请求拆分为多个较小的并行请求
优化示例:一家媒体公司通过批量处理内容审核请求,将每日API成本从$95降至$48,降幅接近50%。
5. 预置吞吐量最佳实践
- 容量规划:根据历史使用模式精确计算所需模型单元
- 承诺折扣:评估长期使用需求,选择适当的承诺期限获取最大折扣
- 混合策略:结合使用预置吞吐量和按需付费,应对流量波动
成本对比:对于稳定负载,6个月承诺的预置吞吐量可比按需付费节省约28%,12个月承诺可节省高达35%。
6. 使用AWS其他服务削减成本
- Lambda函数:使用无服务器函数处理请求前的预处理和优化
- S3+Athena:使用成本更低的存储和查询服务存储和分析结果
- CloudFront:通过CDN缓存静态内容和API响应
架构优化:结合AWS服务的整体架构优化可实现额外15-25%的成本节约。
7. 监控与成本分析
- CloudWatch指标:设置详细的使用监控和告警
- 成本标签:使用标签分配成本到不同业务部门或项目
- 使用分析:定期审查使用模式,识别优化机会
最佳实践:建立每周成本审查流程,实时调整资源分配和使用策略。
【常见问题】AWS Claude模型使用FAQ
Q1: AWS Bedrock上的Claude与直接使用Anthropic API有什么区别?
A1: 基础价格相似,但AWS Bedrock提供更好的企业级集成、区域可用性和账单合并。AWS还提供预置吞吐量选项,适合高流量应用节省成本。
Q2: 如何在AWS Bedrock上快速开始使用Claude模型?
A2: 首先需要有AWS账户,然后在AWS控制台中请求访问Amazon Bedrock服务。获得访问权限后,通过控制台或AWS SDK即可使用Claude模型。AWS提供完善的文档和示例代码加速开发。
Q3: 预置吞吐量模式适合什么类型的应用?
A3: 预置吞吐量适合具有稳定、可预测工作负载的应用,比如生产环境中的客服机器人、内容审核系统或处理固定数量文档的自动化流程。如果每小时的请求数相对稳定,且对延迟敏感,预置吞吐量通常是更经济的选择。
Q4: AWS上使用Claude最常见的陷阱是什么?
A4: 最常见的陷阱包括:
- 低估输入token数量,尤其是使用大型上下文窗口时
- 没有设置适当的输出token限制,导致不必要的长回复
- 忽略了区域选择对延迟和数据传输成本的影响
- 未充分利用AWS的集成服务来优化整体架构
【企业案例】真实应用中的AWS Claude成本管理
案例1:大型金融机构的客户服务转型
一家拥有超过500万客户的银行实施了基于Claude 3.5的客户服务解决方案:
挑战:每天处理超过5万次客户查询,成本控制是主要关注点 解决方案:
- 使用Claude 3.5 Haiku处理80%的常见问题
- 仅将复杂查询升级到Claude 3.5 Sonnet
- 实施全面的响应缓存策略
- 采用6个月预置吞吐量承诺
成果:
- 每月节省超过$45,000(相比全部使用高端模型)
- 客户满意度提高15%
- 系统可靠性达到99.98%
案例2:媒体内容审核平台
一家内容平台每日审核超过10万篇用户生成内容:
挑战:需要高准确度但对成本敏感 解决方案:
- 实施两级审核系统:轻量模型初筛+重点内容深度审核
- 批量处理非实时内容
- 优化提示词指令减少token使用
- 使用AWS Lambda进行请求预处理和后处理
成果:
- API成本降低45%
- 处理时间减少30%
- 准确率保持在98%以上
【总结】选择最适合的AWS Claude策略
Claude在AWS平台上提供了强大而灵活的大语言模型能力,通过合理规划可以在保持高性能的同时控制成本:
- 了解价格结构:掌握按需与预置吞吐量两种模式的特点
- 匹配任务与模型:根据任务复杂度选择最合适的模型,不要过度使用高端模型
- 优化输入输出:精简提示词,限制输出长度
- 利用AWS生态:结合其他AWS服务创建高效架构
- 持续监控与优化:定期分析使用模式,识别优化机会
🌟 专家提示:随着大语言模型市场的快速发展,价格竞争将持续加剧。定期评估不同平台和模型的成本效益,确保您的AI策略保持竞争力。
【实用资源】AWS Claude开发者工具与支持
为帮助您更高效地使用AWS Claude,以下是一些实用资源:
国内开发者福利:API服务推荐
如果您在国内开发环境中难以直接访问AWS服务,可以考虑使用中转API服务,为您提供稳定、快速的API访问体验。
推荐服务:laozhang.ai - 支持Claude、GPT、Gemini、DeepSeek等所有主流大模型,国内直接使用,注册就送美金额度,免费测试。
* 通过此链接注册即可获得额外优惠
如果您需要更多API使用相关服务,还可以联系:
- AWS账号代注册
- Claude API代充值
- AWS技术支持代购
联系方式:微信 ghj930213 或在线下单:https://gpt.aihaoma.cc/
【更新日志】持续优化的见证
hljs plaintext┌─ 更新记录 ──────────────────────────┐ │ 2025-03-18:首次发布完整分析指南 │ │ 2025-03-15:收集AWS最新价格数据 │ │ 2025-03-10:整理企业应用案例 │ └─────────────────────────────────────┘
🔔 特别提示:本文将根据AWS定价变动持续更新,建议收藏本页面,定期查看最新内容!